|
OpenCV 4.10.0
开源计算机视觉库
|
加载中...
搜索中...
没有匹配项
|
OpenCV 4.10.0
开源计算机视觉库
|
在本章节中
思考一下下面的图片,其中包含两种类型的数据,红色和蓝色。在 kNN 中,对于测试数据,我们通常测量其与所有训练样本的距离,然后选出距离最短的一个。测量所有距离需要大量时间,而存储所有训练样本需要大量内存。但是考虑到图中给出的数据,我们是否需要这么多?
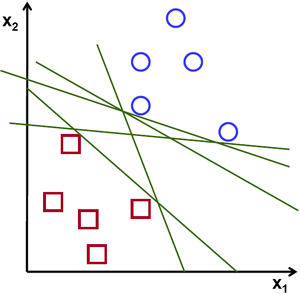
考虑另一个想法。我们找到一条线 \(f(x)=ax_1+bx_2+c\),将两种数据划分为两个区域。当我们得到一个新的测试数据 \(X\) 时,只需将其代入 \(f(x)\) 中。如果 \(f(X) > 0\),则它属于蓝色组,否则它属于红色组。我们可以称这条线为**决策边界**。它非常简单,并且对内存要求不高。可以被直线(或更高维度中的超平面)划分为两部分的此类数据称为**线性可分**。
因此,在上面的图片中,你可以看到有很多这样的线是可能的。我们选择哪条线?我们凭直觉可以说,这条线应该尽可能远地经过所有点。为什么?因为输入数据中可能会存在噪声。此数据不应影响分类准确度。因此,取一条最远的线将提供更多的抗噪能力。因此,SVM 所做的就是找到一条与训练样本最小距离最大的直线(或超平面)。请看下图中经过中心的粗线。
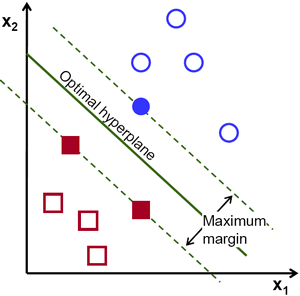
因此,要找到这个决策边界,你需要训练数据。你是否需要所有数据?不。仅需要那些靠近相反组的数据就足够了。在我们的图片中,它们是一个填充蓝色的圆圈和两个填充红色的正方形。我们可以称它们为**支持向量**,而穿过它们的线称为**支持平面**。它们足以找到我们的决策边界。我们不必担心所有数据。它有助于进行数据缩减。
事件发生时,首先找到两个最能代表数据的超平面。例如,蓝色数据表示为 \(w^Tx+b_0 > 1\),而红色数据表示为 \(w^Tx+b_0 < -1\),其中 \(w\) 是权重向量(\(w=[w_1, w_2,..., w_n]\))和 \(x\) 是特征向量(\(x = [x_1,x_2,..., x_n]\))。\(b_0\) 是偏差。权重向量确定决策边界的方向,而偏差点确定决策边界的所在位置。现在决策边界被定义为在这些超平面之间的一半,因此表示为 \(w^Tx+b_0 = 0\)。支持向量到决策边界的最小距离由 \(distance_{support \, vectors}=\frac{1}{||w||}\) 给出。间距是这段距离的两倍,我们需要最大化此间距。即我们需要最小化具有以下限制条件的新函数\(L(w, b_0)\)
\[\min_{w, b_0} L(w, b_0) = \frac{1}{2}||w||^2 \; \text{subject to} \; t_i(w^Tx+b_0) \geq 1 \; \forall i\]
其中 \(t_i\) 是每个类的标签,\(t_i \in [-1,1]\)。
考虑一些不能用直线划分为两个部分的数据。例如,考虑一维数据,“X”在 -3 和 +3,“O”在 -1 和 +1。显然,它不是线性可分的。但有一些方法可以解决这类问题。如果我们可以用函数 \(f(x) = x^2\) 映射这个数据集,我们得到在 9 处的“X”和在 1 处的“O”,它们是线性可分的。
否则,我们可以将一维数据转换为二维数据。我们可以使用函数 \(f(x)=(x,x^2)\) 映射此数据。然后,“X”变为 (-3,9) 和 (3,9),而“O”变为 (-1,1) 和 (1,1)。这也是线性可分的。简而言之,在低维空间中,非线性可分离数据的可能性更大,而在高维空间中,非线性可分离数据更有可能变为线性可分离数据。
总的来说,可以将 d 维空间中的点映射到某些 D 维空间 \((D>d)\) 来检查线性可分性的可能性。有一个想法有助于通过在低维输入(特征)空间中执行计算来计算高维(核)空间中的点积。我们可以用以下示例来说明。
考虑二维空间中的两个点 \(p=(p_1,p_2)\) 和 \(q=(q_1,q_2)\)。令 \(\phi\) 是一个映射函数,它将一个二维点映射到三维空间,如下所示
\[\phi (p) = (p_{1}^2,p_{2}^2,\sqrt{2} p_1 p_2) \phi (q) = (q_{1}^2,q_{2}^2,\sqrt{2} q_1 q_2)\]
让我们定义一个核函数 \(K(p,q)\),它对两个点进行点积,如下所示
\[ \begin{aligned} K(p,q) = \phi(p).\phi(q) &= \phi(p)^T \phi(q) \\ &= (p_{1}^2,p_{2}^2,\sqrt{2} p_1 p_2).(q_{1}^2,q_{2}^2,\sqrt{2} q_1 q_2) \\ &= p_{1}^2 q_{1}^2 + p_{2}^2 q_{2}^2 + 2 p_1 q_1 p_2 q_2 \\ &= (p_1 q_1 + p_2 q_2)^2 \\ \phi(p).\phi(q) &= (p.q)^2 \end{aligned} \]
这意味着,三维空间中的点积可以使用二维空间中的平方点积来完成。这可以应用到更高维度的空间。因此,我们可以从低维度本身计算高维度特征。一旦将它们映射完,我们会得到一个更高维度的空间。
除了所有这些概念之外,还会出现错误分类的问题。因此,仅找到具有最大裕度的决策边界是不够的。我们还需要考虑分类错误的问题。有时,可能找到具有较小裕度的决策边界,但分类错误更少。无论如何,我们需要修改模型,使其找到具有最大裕度但分类错误较少的决策边界。修改后的最小化标准如下:
\[最小值 \; ||w||^2 + C(到其正确区域的误分类样本距离)\]
下图显示了这个概念。为训练数据中的每个样本定义一个新参数\(\xi_i\)。它是从其相应的训练样本到其正确决策区域的距离。对于那些没有被错误分类的样本来说,它们落在相应的支持平面上,因此它们的距离为零。
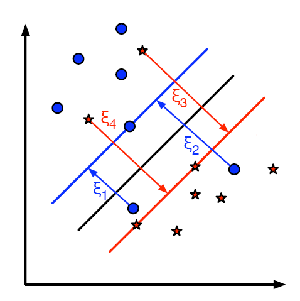
因此,新的优化问题是
\[\最小值_{w, b_{0}} L(w,b_0) = ||w||^{2} + C \sum_{i} {\xi_{i}} \text{满足} y_{i}(w^{T} x_{i} + b_{0}) \geq 1 - \xi_{i} \text{并且} \xi_{i} \geq 0 \text{ } \forall i\]
应该如何选择参数 C?很明显,对这个问题的回答取决于训练数据的分布情况。尽管没有通用的答案,但考虑以下规则是有用的
 1.9.8
1.9.8