|
OpenCV 4.12.0
开源计算机视觉
|
加载中...
搜索中...
无匹配项
|
OpenCV 4.12.0
开源计算机视觉
|
在本章中,我们将理解 K-Means 聚类的概念、它是如何工作的等等。
我们将用一个常用的例子来处理这个问题。
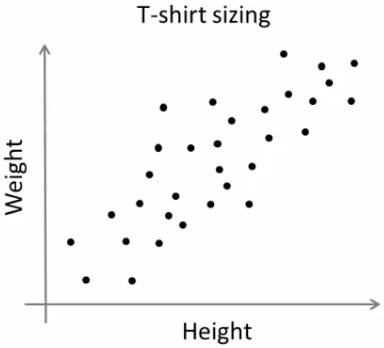
假设有一家公司,打算向市场发布一款新的 T 恤。显然,他们必须生产不同尺寸的型号,以满足所有尺寸的人。因此,该公司收集了人们的身高和体重数据,并将它们绘制在图表上,如下所示
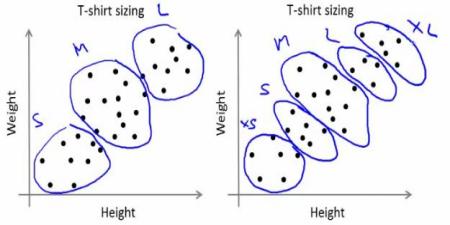
公司无法生产所有尺寸的 T 恤。相反,他们将人们划分为小号、中号和大号,并且只生产这 3 种型号,以适应所有人。这种将人们分成三组的做法可以通过 k-means 聚类来完成,该算法为我们提供了最佳的 3 个尺寸,这将满足所有人。如果它没有满足,公司可以将人们分成更多组,可能是五组,等等。查看下图
该算法是一个迭代过程。我们将借助图像逐步解释它。
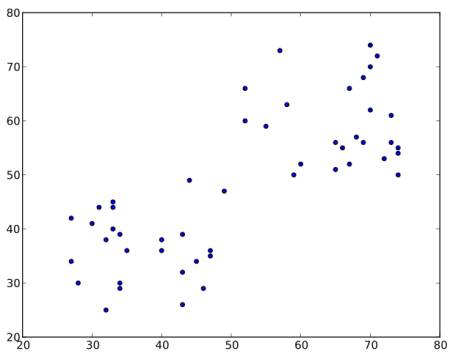
考虑一组数据如下(您可以将其视为 T 恤问题)。我们需要将此数据聚类成两组。
步骤 1 - 算法随机选择两个质心,\(C1\) 和 \(C2\)(有时,任何两个数据都被视为质心)。
步骤 2 - 它计算每个点到两个质心的距离。如果一个测试数据更接近 \(C1\),那么该数据被标记为“0”。如果它更接近 \(C2\),则标记为“1”(如果有更多的质心,则标记为“2”、“3”等)。
在我们的例子中,我们将用红色标记所有标记为“0”的点,用蓝色标记标记为“1”的点。因此,在上述操作之后,我们得到以下图像。
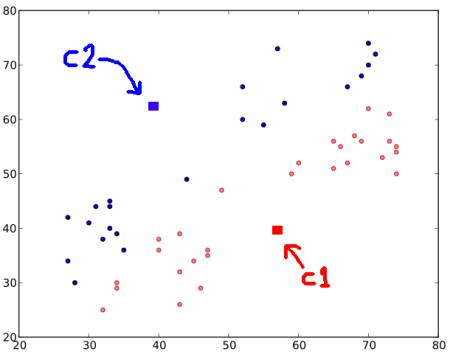
步骤 3 - 接下来,我们分别计算所有蓝色点和红色点的平均值,这将是我们的新质心。也就是说,\(C1\) 和 \(C2\) 移动到新计算的质心。(请记住,显示的图像不是真实值,也不是真实比例,仅用于演示)。
再次,使用新的质心执行步骤 2,并将数据标记为“0”和“1”。
因此,我们得到如下结果
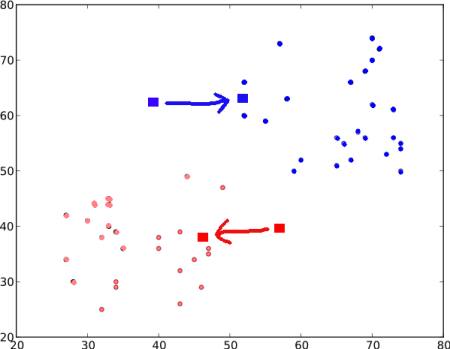
现在,重复执行步骤 2 和步骤 3,直到两个质心都收敛到固定点。(或者可以根据我们提供的标准停止,例如最大迭代次数,或者达到特定精度等) 这些点的特点是,测试数据与其对应质心之间的距离之和最小。或者简单地说,\(C1 \leftrightarrow Red\_Points\) 和 \(C2 \leftrightarrow Blue\_Points\) 之间的距离之和最小。
\[minimize \;\bigg[J = \sum_{All\: Red\_Points}distance(C1,Red\_Point) + \sum_{All\: Blue\_Points}distance(C2,Blue\_Point)\bigg]\]
最终结果几乎如下所示
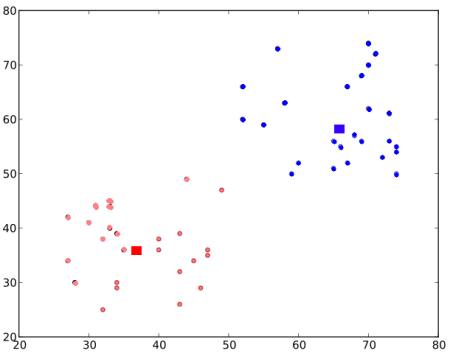
因此,这只是对 K-Means 聚类的一个直观的理解。有关更多详细信息和数学解释,请阅读任何标准机器学习教科书或查看其他资源中的链接。这只是 K-Means 聚类的一个顶层。对该算法有很多修改,例如如何选择初始质心,如何加快迭代过程等。