|
OpenCV 4.10.0
开源计算机视觉
|
加载中...
搜索中...
无匹配项
|
OpenCV 4.10.0
开源计算机视觉
|
上一教程: 条形码识别
下一教程: 非线性可分数据的支持向量机
| 原作者 | Fernando Iglesias García |
| 兼容性 | OpenCV >= 3.0 |
本教程将讲授如何
支持向量机 (SVM) 是一种区分分类器,其形式上由分隔超平面定义。换句话说,给定标记的训练数据(有监督学习),该算法将输出一个最优超平面,该超平面可以对新样本进行分类。
在此过程中获取的超平面有何最优之处?我们考虑以下简单问题
对于一组可线性分类的 2D 点(属于两类中的某一类),找到一条分界直线。
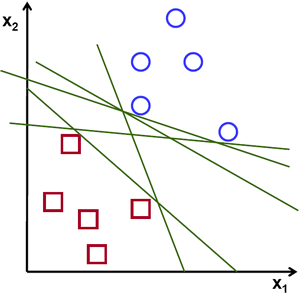
在上图中,你可以看到存在多条线能够解决这个问题。那么有没有哪一条更好呢?我们直观上可以定义一个标准来评价这些直线:如果一条线离这些点太近,那么它就不好,因为它容易受噪声影响,而且它不能正确推广。因此,我们的目标应该是找到一条尽可能远离所有点的直线。
这样,SVM 算法操作的基础就是找到一条与训练样本距离最大的超平面。超平面到样本的距离有另一个重要的名称,即 最大间隔,在 SVM 理论中使用。因此,最优分隔超平面最大化了训练数据的最大间隔。
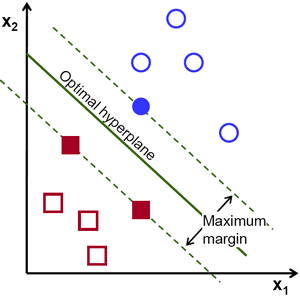
我们引入正式定义超平面的符号
\[f(x) = \beta_{0} + \beta^{T} x,\]
其中 \(\beta\) 被称为权重向量,\(\beta_{0}\) 被称为偏差。
可以通过缩放 \(\beta\) 和 \(\beta_{0}\) 以无穷多种不同的方式表示最佳超平面。根据惯例,在所有可能的超平面表示形式中,选择
\[|\beta_{0} + \beta^{T} x| = 1\]
其中 \(x\) 表示训练集中最接近超平面的训练样本。通常,最接近超平面的训练样本被称为支持向量。这种表示形式称为规范超平面。
现在,我们使用几何学中的结果,它给出了点 \(x\) 到超平面 \((\beta, \beta_{0})\) 的距离
\[\mathrm{distance} = \frac{|\beta_{0} + \beta^{T} x|}{||\beta||}.\]
特别是,对于规范超平面,分子等于 1,到支持向量的距离为
\[\mathrm{distance}_{\text{ support vectors}} = \frac{|\beta_{0} + \beta^{T} x|}{||\beta||} = \frac{1}{||\beta||}.\]
回想在前一节中引入的间距,这里表示为 \(M\),它是最接近样本距离的两倍
\[M = \frac{2}{||\beta||}\]
最后,最大化 \(M\) 的问题等价于在某些约束下最小化函数 \(L(\beta)\) 的问题。约束对超平面对所有训练样本 \(x_{i}\) 进行正确分类的要求进行建模。形式上,
\[\min_{\beta, \beta_{0}} L(\beta) = \frac{1}{2}||\beta||^{2} \text{ subject to } y_{i}(\beta^{T} x_{i} + \beta_{0}) \geq 1 \text{ } \forall i,\]
其中 \(y_{i}\) 表示训练样本的各个标签。
这是一个拉格朗日最优化问题,可以使用拉格朗日乘数来求解,以获得最优超平面的权重向量 \(\beta\) 和偏差 \(\beta_{0}\)。
本习题的训练数据由一组标记的二维点组成,这些点属于两个不同的类别之一;一个类别包含一个点,另一个类别包含三个点。
稍后将使用的函数 cv::ml::SVM::train 要求训练数据存储为 cv::Mat 浮点数对象。因此,我们会根据上面定义的数组创建这些对象
设置 SVM 的参数
在本教程中,我们以训练示例被划分为线性可分的两种类的最简单情况下介绍了支持向量机的理论。然而,支持向量机可用于各种问题(例如,非线性可分数据问题、使用核函数提升示例维度的支持向量机等)。因此,我们在训练支持向量机之前需要定义一些参数。这些参数存储在类 cv::ml::SVM 的对象中。
此处
支持向量机分类的区域
方法 cv::ml::SVM::predict 用于使用经过训练的支持向量机对输入样本进行分类。在这个示例中,我们使用此方法根据支持向量机的预测为空间着色。换言之,遍历一张图像,将图像的像素解释为笛卡尔平面的点。每个点根据支持向量机预测的类别着色;如果属于标签为 1 的类别,则着成绿色;如果属于标签为 -1 的类别,则着成蓝色。
支持向量
我们在此处使用一对方法来获取支持向量的相关信息。方法 cv::ml::SVM::getSupportVectors 能够获取所有支持向量。我们在此使用这些方法来查找作为支持向量的训练示例并突出显示了它们。

 1.9.8 为 OpenCV 生成
1.9.8 为 OpenCV 生成