|
OpenCV 4.11.0
开源计算机视觉
|
加载中…
搜索中…
未找到匹配项
|
OpenCV 4.11.0
开源计算机视觉
|
在机器学习算法中,存在训练数据的概念。训练数据包含几个组成部分:
如您所见,训练数据可能具有相当复杂的结构;此外,它可能非常大且/或并非完全可用,因此需要对这个概念进行抽象。在OpenCV ml中,有cv::ml::TrainData 类用于此目的。
这个简单的分类模型假设每个类别的特征向量都服从正态分布(尽管不一定独立分布)。因此,整个数据分布函数被假设为高斯混合模型,每个类别一个分量。该算法使用训练数据估计每个类别的均值向量和协方差矩阵,然后将其用于预测。
该算法缓存所有训练样本,并通过使用投票、计算加权和等方法分析样本的特定数量 (K) 的最近邻来预测新样本的响应。该方法有时被称为“示例学习”,因为为了预测,它寻找与给定向量最接近的具有已知响应的特征向量。
最初,支持向量机 (SVM) 是一种构建最优二元(两类)分类器的技术。后来,该技术扩展到回归和聚类问题。SVM是基于核方法的特例。它使用核函数将特征向量映射到更高维的空间,并在该空间中构建最优线性判别函数或拟合训练数据的最优超平面。在SVM的情况下,核函数不是显式定义的。相反,需要定义超空间中任意两点之间的距离。
该解决方案是最优的,这意味着分离超平面与来自两类(在两类分类器的情况下)的最近特征向量之间的裕度最大。最接近超平面的特征向量称为支持向量,这意味着其他向量的位置不会影响超平面(决策函数)。
OpenCV 中的 SVM 实现基于 [50]
应使用 StatModel::predict(samples, results, flags)。传递 flags=StatModel::RAW_OUTPUT 以从 SVM 获取原始响应(在回归、一类或两类分类问题的情况下)。
本节中讨论的 ML 类实现了 [40] 中描述的分类和回归树算法。
cv::ml::DTrees 类表示单个决策树或决策树集合。它也是 RTrees 和 Boost 的基类。
决策树是二叉树(每个非叶节点有两个子节点的树)。它可以用于分类或回归。对于分类,每个树叶都标记有类别标签;多个叶可能具有相同的标签。对于回归,也会为每个树叶分配一个常数,因此逼近函数是分段常数的。
为了到达叶节点并获得输入特征向量的响应,预测过程从根节点开始。从每个非叶节点,该过程向左(选择左子节点作为下一个观察节点)或向右,这取决于存储在观察节点中的某个变量的值。可能的变量有:
因此,在每个节点中,使用一对实体(变量索引,决策规则(阈值/子集))。这组对称为分割(在变量变量索引上分割)。到达叶节点后,分配给该节点的值将用作预测过程的输出。
有时,输入向量的某些特征会丢失(例如,在黑暗中很难确定物体的颜色),预测过程可能会卡在某个节点(在上述示例中,如果节点按颜色分割)。为了避免这种情况,决策树使用所谓的替代分割。也就是说,除了最好的“主要”分割之外,每个树节点还可以分割到一个或多个其他变量,其结果几乎相同。
树模型是递归构建的,从根节点开始。所有训练数据(特征向量和响应)都用于分割根节点。在每个节点中,根据某些标准找到最佳决策规则(最佳“主要”分割)。在机器学习中,基尼“纯度”标准用于分类,而平方误差和用于回归。然后,如有必要,找到替代分割。它们类似于训练数据上主要分割的结果。所有数据都使用主要分割和替代分割(如同在预测过程中所做的那样)划分为左子节点和右子节点。然后,该过程递归地分割左右两个子节点。在每个节点处,递归过程可能会在以下情况下停止(即,停止进一步分割节点)
构建树后,如有必要,可以使用交叉验证过程对其进行剪枝。也就是说,可能会导致模型过拟合的树的一些分支被剪掉。通常,此过程仅应用于独立的决策树。通常,树集成构建的树足够小,并使用其自身的保护方案来防止过拟合。
除了预测是决策树的明显用途之外,树还可以用于各种数据分析。构建的决策树算法的关键特性之一是能够计算每个变量的重要性(相对决定性)。例如,在使用消息中出现的一组词作为特征向量的垃圾邮件过滤器中,变量重要性评级可用于确定最能“指示垃圾邮件”的词,从而有助于保持字典大小合理。
每个变量的重要性是在树中所有关于此变量的分割(主要分割和替代分割)上计算的。因此,为了正确计算变量的重要性,即使没有缺失数据,也必须在训练参数中启用替代分割。
一个常见的机器学习任务是监督学习。在监督学习中,目标是学习输入\(x\)和输出\(y\)之间的函数关系\(F: y = F(x)\)。预测定性输出称为分类,而预测定量输出称为回归。
Boosting 是一种强大的学习概念,它为监督分类学习任务提供了解决方案。它结合了许多“弱”分类器的性能以产生一个强大的委员会[273]。弱分类器只需要比机会好,因此可以非常简单且计算成本低廉。但是,许多弱分类器巧妙地将结果组合成一个强分类器,该分类器通常优于大多数“单片”强分类器,例如 SVM 和神经网络。
决策树是提升方案中最常用的弱分类器。通常,每个树只有一个分割节点的最简单的决策树(称为桩)就足够了。
提升模型基于\(N\)个训练样本\({(x_i,y_i)}1N\) ,其中\(x_i \in{R^K}\)且\(y_i \in{-1, +1}\)。\(x_i\)是一个\(K\)分量向量。每个分量都编码与手头学习任务相关的特征。所需的二元输出编码为 -1 和 +1。
不同的提升变体被称为离散 AdaBoost、实数 AdaBoost、LogitBoost 和 Gentle AdaBoost [95]。它们在其整体结构上非常相似。因此,本章仅关注下面概述的标准二元离散 AdaBoost 算法。最初,每个样本都分配相同的权重(步骤 2)。然后,在加权训练数据上训练弱分类器\(f_{m(x)}\)(步骤 3a)。计算其加权训练误差和缩放因子\(c_m\)(步骤 3b)。增加误分类的训练样本的权重(步骤 3c)。然后对所有权重进行归一化,并继续寻找下一个弱分类器,再进行\(M\) -1 次。最终分类器\(F(x)\)是单个弱分类器加权和的符号(步骤 4)。
二元离散 AdaBoost 算法
为了减少提升模型的计算时间而不会显着降低精度,可以使用影响修剪技术。随着训练算法的进行和集成中树的数量的增加,越来越多的训练样本被正确分类并且置信度越来越高,因此这些样本在后续迭代中接收到的权重较小。相对权重非常低的样本对弱分类器训练的影响很小。因此,在弱分类器训练期间可以排除此类样本,而不会对诱导分类器产生太大影响。此过程由 `weight_trim_rate` 参数控制。弱分类器训练中仅使用总权重质量的汇总分数 `weight_trim_rate` 的样本。请注意,在每次训练迭代中都会重新计算**所有**训练样本的权重。在特定迭代中删除的样本可能会再次用于学习一些弱分类器[95]
应使用`StatModel::predict(samples, results, flags)`。传递 `flags=StatModel::RAW_OUTPUT` 以获取来自 Boost 分类器的原始总和。
随机树由 Leo Breiman 和 Adele Cutler 引入:http://www.stat.berkeley.edu/users/breiman/RandomForests/。该算法可以处理分类和回归问题。随机树是树预测器的集合(集成),在本节中进一步称为森林(该术语也是由 L. Breiman 引入的)。分类的工作原理如下:随机树分类器获取输入特征向量,使用森林中的每棵树对其进行分类,并输出获得大多数“投票”的类标签。在回归的情况下,分类器响应是森林中所有树的响应的平均值。
所有树都使用相同的参数进行训练,但使用不同的训练集。这些训练集是使用bootstrap方法从原始训练集生成的:对于每个训练集,您随机选择与原始集合相同数量的向量(=N)。向量是有放回地选择的。也就是说,有些向量会多次出现,有些则缺失。在每棵训练树的每个节点上,并非所有变量都用于寻找最佳分割,而只是一些随机子集。每个节点都会生成一个新的子集。但是,其大小对于所有节点和所有树都是固定的。默认情况下,它是一个训练参数,设置为\(\sqrt{number\_of\_variables}\)。没有修剪任何构建的树。
在随机树中,不需要任何精度估计过程,例如交叉验证或bootstrap,或者不需要单独的测试集来估计训练误差。误差在训练期间内部估计。当使用有放回抽样绘制当前树的训练集时,一些向量会被遗漏(所谓的oob(包外)数据)。oob数据的规模约为N/3。分类误差的估计方法如下:
有关随机树用法的示例,请参阅OpenCV发行版中的letter_recog.cpp示例。
参考文献
期望最大化 (EM) 算法估计多元概率密度函数的参数,其形式为具有指定混合数的混合高斯分布。
考虑来自d维欧几里得空间的一组N个特征向量{ \(x_1, x_2,...,x_{N}\) },它们是从高斯混合中抽取的
\[p(x;a_k,S_k, \pi _k) = \sum _{k=1}^{m} \pi _kp_k(x), \quad \pi _k \geq 0, \quad \sum _{k=1}^{m} \pi _k=1,\]
\[p_k(x)= \varphi (x;a_k,S_k)= \frac{1}{(2\pi)^{d/2}\mid{S_k}\mid^{1/2}} exp \left \{ - \frac{1}{2} (x-a_k)^TS_k^{-1}(x-a_k) \right \} ,\]
其中\(m\)是混合的数量,\(p_k\)是均值为\(a_k\)且协方差矩阵为\(S_k\)的正态分布密度,\(\pi_k\)是第k个混合的权重。给定混合数\(M\)和样本\(x_i\),\(i=1..N\),该算法找到所有混合参数的最大似然估计 (MLE),即\(a_k\)、\(S_k\)和\(\pi_k\)
\[L(x, \theta )=logp(x, \theta )= \sum _{i=1}^{N}log \left ( \sum _{k=1}^{m} \pi _kp_k(x) \right ) \to \max _{ \theta \in \Theta },\]
\[\Theta = \left \{ (a_k,S_k, \pi _k): a_k \in \mathbbm{R} ^d,S_k=S_k^T>0,S_k \in \mathbbm{R} ^{d \times d}, \pi _k \geq 0, \sum _{k=1}^{m} \pi _k=1 \right \} .\]
EM算法是一个迭代过程。每次迭代都包括两个步骤。在第一步(期望步骤或E步骤)中,您使用当前可用的混合参数估计来找到样本i属于混合k的概率\(p_{i,k}\)(在下式中记为\(\alpha_{i,k}\))
\[\alpha _{ki} = \frac{\pi_k\varphi(x;a_k,S_k)}{\sum\limits_{j=1}^{m}\pi_j\varphi(x;a_j,S_j)} .\]
在第二步(最大化步骤或M步骤)中,使用计算出的概率来改进混合参数估计
\[\pi _k= \frac{1}{N} \sum _{i=1}^{N} \alpha _{ki}, \quad a_k= \frac{\sum\limits_{i=1}^{N}\alpha_{ki}x_i}{\sum\limits_{i=1}^{N}\alpha_{ki}} , \quad S_k= \frac{\sum\limits_{i=1}^{N}\alpha_{ki}(x_i-a_k)(x_i-a_k)^T}{\sum\limits_{i=1}^{N}\alpha_{ki}}\]
或者,当可以提供\(p_{i,k}\)的初始值时,算法可以从M步骤开始。当\(p_{i,k}\)未知时的另一种方法是使用更简单的聚类算法对输入样本进行预聚类,从而获得初始\(p_{i,k}\)。通常(包括机器学习)为此目的使用k均值算法。
EM算法的主要问题之一是要估计大量的参数。大多数参数都存在于协方差矩阵中,每个协方差矩阵都是\(d \times d\)个元素,其中\(d\)是特征空间维数。但是,在许多实际问题中,协方差矩阵接近对角线,甚至接近\(\mu_k*I\),其中\(I\)是单位矩阵,\(\mu_k\)是依赖于混合的“尺度”参数。因此,稳健的计算方案可以从对协方差矩阵施加更严格的约束开始,然后使用估计的参数作为较少约束的优化问题的输入(通常对角协方差矩阵已经足够好的近似)。
参考文献
ML实现前馈人工神经网络,或者更具体地说,是多层感知器 (MLP),这是最常用的神经网络类型。MLP由输入层、输出层和一个或多个隐藏层组成。MLP的每一层都包含一个或多个神经元,这些神经元与前一层和下一层的神经元定向连接。下面的示例表示一个三层感知器,它有三个输入、两个输出和一个包含五个神经元的隐藏层。
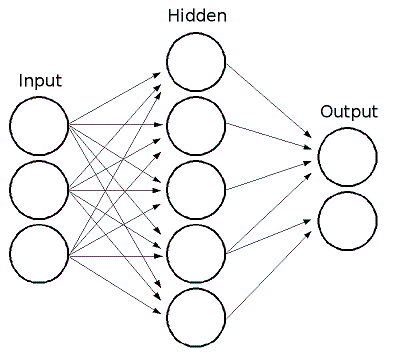
MLP中的所有神经元都是相似的。它们每个都有几个输入链接(它将前一层中几个神经元的输出值作为输入)和几个输出链接(它将响应传递给下一层中几个神经元)。从前一层检索到的值与每个神经元的特定权重相加,再加上偏差项。该和使用激活函数\(f\)进行转换,该函数对于不同的神经元也可能不同。
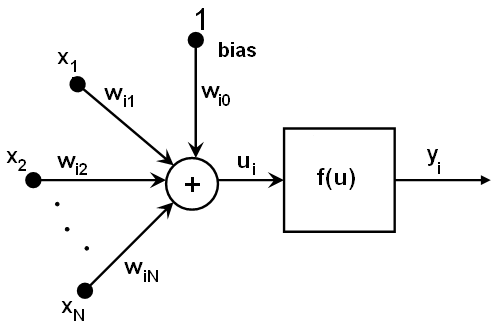
换句话说,给定第\(n\)层的输出\(x_j\),第\(n+1\)层的输出\(y_i\)计算如下:
\[u_i = \sum _j (w^{n+1}_{i,j}*x_j) + w^{n+1}_{i,bias}\]
\[y_i = f(u_i)\]
可以使用不同的激活函数。ML实现了三个标准函数
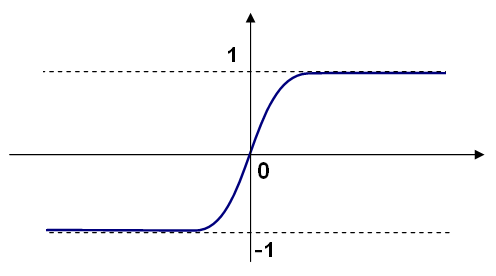
在ML中,所有神经元都具有相同的激活函数,具有相同的自由参数(\(\alpha, \beta\)),这些参数由用户指定,不会被训练算法更改。
因此,整个训练后的网络的工作原理如下:
因此,要计算网络,需要知道所有权重\(w^{n+1)}_{i,j}\)。权重由训练算法计算。该算法采用训练集、多个具有对应输出向量的输入向量,并迭代调整权重,使网络能够对提供的输入向量给出期望的响应。
网络规模越大(隐藏层的数量和大小),潜在的网络灵活性就越大。训练集上的误差可以任意减小。但同时,学习到的网络也“学习”了训练集中的噪声,因此,当网络规模达到一定限度后,测试集上的误差通常开始增加。此外,大型网络的训练时间比小型网络长得多,因此可以使用cv::PCA或类似技术对数据进行预处理,并在仅包含基本特征的较小网络上进行训练是合理的。
另一个MLP的特性是无法直接处理分类数据。但是,有一种解决方法。如果输入或输出(对于n类分类器\(n>2\))层中的某个特征是分类的,并且可以取\(M>2\)个不同的值,那么将其表示为M个元素的二元组是有意义的,其中第i个元素为1当且仅当该特征等于M个可能值中的第i个值。这增加了输入/输出层的大小,但加快了训练算法的收敛速度,同时允许此类变量的“模糊”值,即概率元组而不是固定值。
ML实现了两种训练MLP的算法。第一种算法是经典的随机顺序反向传播算法。第二种(默认)算法是批量RPROP算法。
ML实现了逻辑回归,这是一种概率分类技术。逻辑回归是一种二元分类算法,与支持向量机 (SVM) 密切相关。与SVM一样,逻辑回归可以扩展到处理多类分类问题,例如数字识别(即从给定图像中识别0,1,2,3,...等数字)。此版本的逻辑回归支持二元和多类分类(对于多类分类,它会创建多个二元分类器)。为了训练逻辑回归分类器,使用了批量梯度下降和 Mini-Batch 梯度下降算法(参见http://en.wikipedia.org/wiki/Gradient_descent_optimization)。逻辑回归是一种判别式分类器(更多详情请参见http://www.cs.cmu.edu/~tom/NewChapters.html)。逻辑回归在 LogisticRegression 中作为 C++ 类实现。
在逻辑回归中,我们试图优化训练参数\(\theta\),以实现假设\(0 \leq h_\theta(x) \leq 1\)。我们有\(h_\theta(x) = g(h_\theta(x))\)和\(g(z) = \frac{1}{1+e^{-z}}\)作为逻辑或 sigmoid 函数。“逻辑”一词在逻辑回归中指的是此函数。对于给定类别为 0 和 1 的二元分类问题的给定数据,如果\(h_\theta(x) \geq 0.5\),则可以确定给定数据实例属于类别 1;如果\(h_\theta(x) < 0.5\),则属于类别 0。
在逻辑回归中,选择正确的参数对于减少训练误差和确保高训练精度至关重要。
逻辑回归分类器的训练参数样本集可以初始化如下