|
OpenCV 4.11.0
开源计算机视觉库
|
加载中…
搜索中…
无匹配项
|
OpenCV 4.11.0
开源计算机视觉库
|
G-API是一个异构框架,提供统一的API来使用多个支持的后端编程图像处理流水线。
关键设计理念是保持流水线代码本身平台无关,同时在图编译(配置)时使用额外的参数指定使用哪些内核以及使用哪些设备。此要求导致了以下架构。
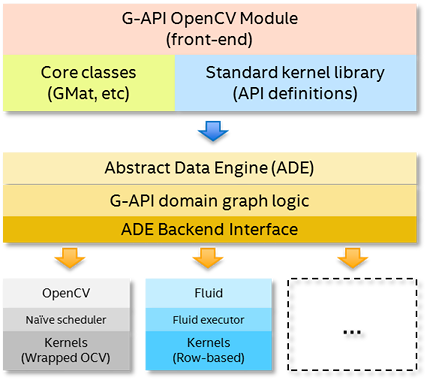
此架构包含三个层:
在定义和使用流水线(在 G-API 术语中为计算)时,用户与 API 层交互。API 层定义了一组 G-API 动态对象,这些对象可用作图中的输入、输出和中间数据对象。
API 层指定了对这些数据对象定义的一系列操作——所谓的内核。有关 G-API 默认提供的操作的详细信息,请参阅 G-API 核心 和 imgproc 命名空间。
G-API 不仅限于这些操作——用户可以使用特殊的宏 G_TYPED_KERNEL()轻松定义自己的内核。
API 层还负责在流水线创建时编组和存储操作参数。除了上述 G-API 动态对象外,操作还可以接受任意参数(更多信息请参见此处),因此 API 层会在执行时捕获其值并在内部存储。
最后,cv::GComputation 和 cv::GCompiled 是 API 层中其余重要的组件。前者将一系列 G-API 表达式包装到一个对象(图)中,而后者是图编译的产物(有关详细信息,请参阅本章)。
每个 G-API 计算在执行之前都会被编译。编译过程通过两种方式触发:
如果预先不知道输入数据格式(例如,来自任意输入文件时),建议使用第一种方法。对于输入数据特性通常预定义的部署(生产)场景,建议使用第二种方法。
图编译过程构建在 ADE 框架之上。最初,从 API 层捕获的表达式生成一个二分图。此图包含两种类型的节点:数据和操作。图始终以数据节点开头和结尾,中间是操作节点。每个操作节点都有输入和输出,两者都是数据节点。
生成初始图后,它实际上由许多图转换(称为通道)处理。ADE 框架充当编译器通道管理引擎,通道是专门为 G-API 编写的。
有不同的通道来检查图的有效性,细化操作和数据的细节,基于亲和力或用户指定的区域划分将节点组织成集群(“岛屿”)[待定]等等。后端也可以将特定于后端的通道注入到编译过程中,有关详细信息,请参阅专用章节。
图编译的结果是一个已编译的对象,由类cv::GCompiled表示。无论是否存在显式或隐式编译请求(见上文),始终都会创建一个新的cv::GCompiled对象。实际的图执行发生在cv::GCompiled内,并由参与图编译的后端确定。
上图列出了两个后端,OpenCV 和 Fluid。OpenCV 被称为“参考后端”,它使用普通的 OpenCV 函数实现 G-API 操作。此后端可用于在熟悉的开发系统上进行原型设计。Fluid 是一个用于在 CPU 上进行缓存高效执行的插件——它实现了一种不同的执行策略,并使用其自身的特殊内核进行操作。Fluid 后端允许在 CPU 上运行时实现更小的内存占用和更好的内存局部性。
可能还有更多可用的后端,例如 Halide、OpenCL 等——G-API 提供了一个统一的内部 API 来开发后端,因此任何爱好者或公司都可以自由地在新的平台或加速器上扩展 G-API。在 OpenCV 基础设施方面,每个新的后端都是一个新的独立 OpenCV 模块,在作为 OpenCV 的一部分构建时扩展 G-API。
图的执行方式由为编译选择的backend定义。事实上,每个后端都在图编译过程的最后阶段构建自己的执行脚本,此时会生成可执行(已编译)对象。例如,在 OpenCV 后端中,此脚本只是一个按拓扑排序的 OpenCV 函数调用序列;对于 Fluid 后端,它也是类似的东西——一个按拓扑排序的Agent列表,在每次迭代中处理输入行。
图执行可以通过两种方式触发
这两种方法都是多态的,并接受可变数量的参数,并在运行时执行有效性检查。如果传递的数据对象的数量、形状和格式与预期不同,则会抛出运行时异常。G-API 还提供类型化包装器以将这些检查移动到编译时——参见 cv::GComputationT<>。
G-API 图执行声明为无状态——这意味着已编译的函子 (cv::GCompiled) 就像一个纯 C++ 函数,并为同一组输入参数提供相同的结果。
这两种执行方法都采用 \(N+M\) 个参数,其中 \(N\) 是输入的数量,\(M\) 是 cv::GComputation 定义的输出数量。请注意,虽然 G-API 类型 (cv::GMat 等) 用于定义,但执行方法接受 OpenCV 的传统数据类型(如 cv::Mat),其中包含实际数据——请参见 参数编组 中的表格。