|
OpenCV 4.12.0
开源计算机视觉
|
加载中...
搜索中...
无匹配项
上一篇教程: 非线性可分数据的支持向量机
| 原始作者 | Theodore Tsesmelis |
| 兼容性 | OpenCV >= 3.0 |
在本教程中,您将学习如何
主成分分析 (PCA) 是一种统计方法,用于提取数据集中最重要的特征。
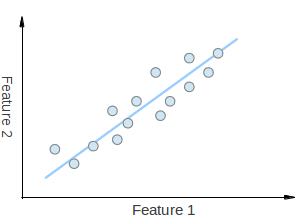
考虑图中的一组二维点。每个维度对应一个您感兴趣的特征。有人可能会争辩说这些点是随机排列的。然而,如果您仔细观察,会发现存在一个难以忽视的线性模式(由蓝线指示)。PCA 的一个关键点是降维。降维是减少给定数据集维度数量的过程。例如,在上述情况下,可以将点集近似为一条直线,从而将给定点的维度从二维降到一维。
此外,您还可以看到这些点沿蓝线的变化最大,比沿特征 1 轴或特征 2 轴的变化更大。这意味着如果您知道点沿蓝线的位置,您将比只知道点在特征 1 轴或特征 2 轴上的位置拥有更多的信息。
因此,PCA 允许我们找到数据变化最大的方向。实际上,对图中点集运行 PCA 的结果是两个向量,称为特征向量,它们是数据集的主成分。
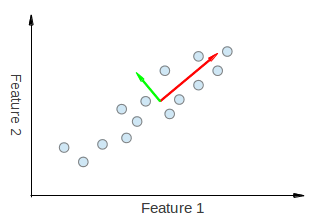
每个特征向量的大小编码在相应的特征值中,并指示数据沿主成分变化的程度。特征向量的起点是数据集中所有点的中心。将 PCA 应用于 N 维数据集会得到 N 个 N 维特征向量、N 个特征值和 1 个 N 维中心点。理论够了,让我们看看如何将这些思想付诸代码。
目标是将给定维度为 p 的数据集 X 转换为维度更小 L 的替代数据集 Y。等效地,我们正在寻找矩阵 Y,其中 Y 是矩阵 X 的 Karhunen–Loève 变换 (KLT)
\[ \mathbf{Y} = \mathbb{K} \mathbb{L} \mathbb{T} \{\mathbf{X}\} \]
组织数据集
假设您有一个包含 p 个变量观测值的数据集,并且您希望减少数据,使得每个观测值仅用 L 个变量描述,其中 L < p。进一步假设数据排列为一组 n 个数据向量 \( x_1...x_n \),其中每个 \( x_i \) 代表 p 个变量的单个分组观测值。
计算经验均值
将计算出的均值放入一个维度为 \( p\times 1 \) 的经验均值向量 u 中。
\[ \mathbf{u[j]} = \frac{1}{n}\sum_{i=1}^{n}\mathbf{X[i,j]} \]
计算与均值的偏差
均值减法是寻找使数据近似的均方误差最小化的主成分基的解决方案中不可或缺的一部分。因此,我们通过以下方式对数据进行中心化处理:
将减去均值后的数据存储在 \( n\times p \) 矩阵 B 中。
\[ \mathbf{B} = \mathbf{X} - \mathbf{h}\mathbf{u^{T}} \]
其中 h 是一个所有元素为 1 的 \( n\times 1 \) 列向量
\[ h[i] = 1, i = 1, ..., n \]
找到协方差矩阵
通过矩阵 B 与自身的外积找到 \( p\times p \) 经验协方差矩阵 C
\[ \mathbf{C} = \frac{1}{n-1} \mathbf{B^{*}} \cdot \mathbf{B} \]
其中 * 是共轭转置运算符。请注意,如果 B 完全由实数组成(许多应用中都是如此),则“共轭转置”与常规转置相同。
找到协方差矩阵的特征向量和特征值
计算使协方差矩阵 C 对角化的特征向量矩阵 V
\[ \mathbf{V^{-1}} \mathbf{C} \mathbf{V} = \mathbf{D} \]
其中 D 是 C 的特征值的对角矩阵。
矩阵 D 将采用 \( p \times p \) 对角矩阵的形式
\[ D[k,l] = \left\{\begin{matrix} \lambda_k, k = l \\ 0, k \neq l \end{matrix}\right. \]
这里,\( \lambda_j \) 是协方差矩阵 C 的第 j 个特征值
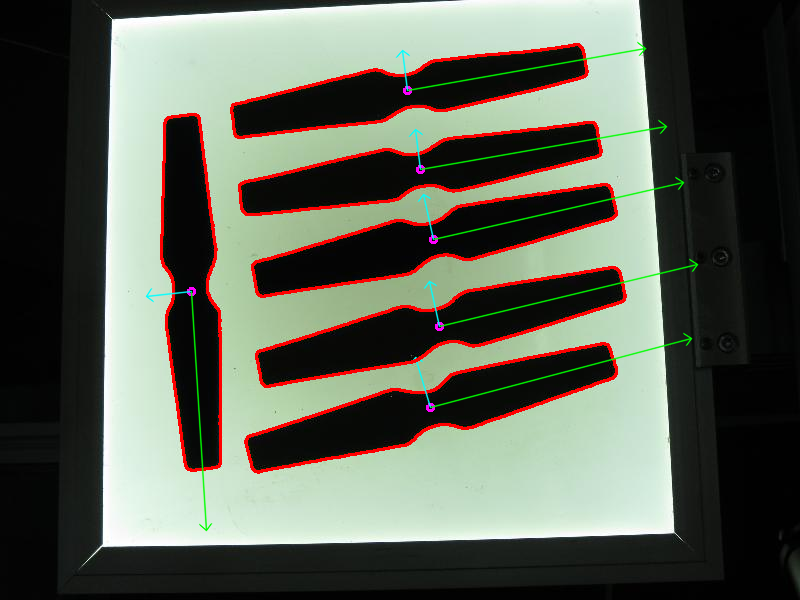
在这里,我们应用必要的预处理程序,以便能够检测感兴趣的对象。
然后通过大小查找和过滤轮廓,并获取剩余轮廓的方向。
通过调用 getOrientation() 函数来提取方向,该函数执行所有 PCA 过程。
首先,数据需要排列成大小为 n x 2 的矩阵,其中 n 是我们拥有的数据点数量。然后我们可以执行 PCA 分析。计算出的均值(即质心)存储在 cntr 变量中,特征向量和特征值存储在相应的 std::vector 中。
最终结果通过 drawAxis() 函数可视化,其中主成分以线条绘制,每个特征向量乘以其特征值并平移到均值位置。
该代码打开一幅图像,查找检测到的感兴趣对象的方向,然后通过绘制检测到的感兴趣对象的轮廓、中心点以及与提取方向相关的 x 轴和 y 轴来可视化结果。