上一篇教程: 使用 G-API 的面部分析管道
下一篇教程: 使用 G-API 实现面部美容算法
简介
在本文教程中,您将学习
- 如何将现有算法转换为 G-API 计算(图);
- 如何检查和分析 G-API 图;
- 如何在不更改其代码的情况下自定义图执行。
本教程基于 通过梯度结构张量进行各向异性图像分割。
快速开始:使用 OpenCV 后端
在开始之前,让我们回顾一下原始算法实现
#include <iostream>
void calcGST(
const Mat& inputImg,
Mat& imgCoherencyOut,
Mat& imgOrientationOut,
int w);
{
int W = 52;
double C_Thr = 0.43;
int LowThr = 35;
int HighThr = 57;
samples::addSamplesDataSearchSubDirectory("doc/tutorials/imgproc/anisotropic_image_segmentation/images");
Mat imgIn = imread(samples::findFile(
"gst_input.jpg"), IMREAD_GRAYSCALE);
{
cout << "错误:图像无法加载..!!" << endl;
返回页 -1;
}
Mat imgCoherency, imgOrientation;
calcGST(imgIn, imgCoherency, imgOrientation, W);
imgCoherencyBin = imgCoherency > C_Thr;
inRange(imgOrientation,
Scalar(LowThr),
Scalar(HighThr), imgOrientationBin);
imgBin = imgCoherencyBin & imgOrientationBin;
normalize(imgCoherency, imgCoherency, 0, 255, NORM_MINMAX,
CV_8U);
normalize(imgOrientation, imgOrientation, 0, 255, NORM_MINMAX,
CV_8U);
imshow("原始", imgIn);
imshow("结果", 0.5 * (imgIn + imgBin));
imshow("一致性", imgCoherency);
imshow("方向", imgOrientation);
imwrite("result.jpg", 0.5*(imgIn + imgBin));
imwrite("Coherency.jpg", imgCoherency);
imwrite("Orientation.jpg", imgOrientation);
waitKey(0);
返回页 0;
}
void calcGST(
const Mat& inputImg,
Mat& imgCoherencyOut,
Mat& imgOrientationOut,
int w)
{
Mat imgDiffX, imgDiffY, imgDiffXY;
Sobel(img, imgDiffX,
CV_32F, 1, 0, 3);
Sobel(img, imgDiffY,
CV_32F, 0, 1, 3);
multiply(imgDiffX, imgDiffY, imgDiffXY);
Mat imgDiffXX, imgDiffYY;
multiply(imgDiffX, imgDiffX, imgDiffXX);
multiply(imgDiffY, imgDiffY, imgDiffYY);
Mat tmp1, tmp2, tmp3, tmp4;
tmp1 = J11 + J22;
tmp2 = J11 - J22;
multiply(tmp2, tmp2, tmp2);
multiply(J12, J12, tmp3);
sqrt(tmp2 + 4.0 * tmp3, tmp4);
lambda1 = tmp1 + tmp4;
lambda1 = 0.5*lambda1;
lambda2 = tmp1 - tmp4;
lambda2 = 0.5*lambda2;
divide(lambda1 - lambda2, lambda1 + lambda2, imgCoherencyOut);
phase(J22 - J11, 2.0*J12, imgOrientationOut, true);
imgOrientationOut = 0.5*imgOrientationOut;
}
bool empty() const
如果数组没有元素,则返回 true。
void convertTo(OutputArray m, int rtype, double alpha=1, double beta=0) const
在不改变尺寸的情况下将数组转换为另一种数据类型。
模板类,用于指定图像或矩形的尺寸。
定义 types.hpp:335
#define CV_8U
定义 interface.h:73
#define CV_32F
定义 interface.h:78
int main(int argc, char *argv[])
定义 highgui_qt.cpp:3
与磁盘上文件的存储相关联的“黑匣子”表示。
定义 core.hpp:102
检查 calcGST()
函数 calcGST() 明显是一条图像处理管道
考虑上述内容,calcGST() 是一个不错的开始候选对象。在原始代码中,其原型定义如下
void calcGST(
const Mat& inputImg,
Mat& imgCoherencyOut,
Mat& imgOrientationOut,
int w);
使用 G-API,我们可以将其定义如下
GMat 类在图像中代表图像或张量数据。
定义 gmat.hpp:68
了解这一点很重要:基于 G-API 的新版 calcGST() 只生成一个计算图,与实际计算值的原始版本相对。这是其中的一个主要区别,即基于 G-API 的函数用于构造图形,而不是处理实际数据。
让我们通过计算 J 矩阵来开始实现 calcGST()。以下是原始代码的样子
void calcGST(
const Mat& inputImg,
Mat& imgCoherencyOut,
Mat& imgOrientationOut,
int w)
{
Mat imgDiffX, imgDiffY, imgDiffXY;
Sobel(img, imgDiffX,
CV_32F, 1, 0, 3);
Sobel(img, imgDiffY,
CV_32F, 0, 1, 3);
multiply(imgDiffX, imgDiffY, imgDiffXY);
这里我们需为每次新的操作声明输出对象(将 img 视为 cv::Mat::convertTo 的结果,imgDiffX 和其他结果为 cv::Sobel 和 cv::multiply 的结果)。
G-API 的类比列在下面
{
GMat Sobel(const GMat &src, int ddepth, int dx, int dy, int ksize=3, double scale=1, double delta=0, int borderType=BORDER_DEFAULT, const Scalar &borderValue=Scalar(0))
使用扩展 Sobel 算子计算第一、二或三阶图像导数或混合图像导数。
GMat mul(const GMat &src1, const GMat &src2, double scale=1.0, int ddepth=-1)
计算两个矩阵的按元素比例乘积。
此代码段演示了 G-API 和传统 OpenCV 之间以下语法差异
- 默认情况下,所有标准 G-API 函数都放置在“cv::gapi”命名空间中;
- G-API 操作会返回结果,无需将其他“输出”参数传递给函数。
注意 - 此代码还使用了auto - 诸如 img、imgDiffX 等中间对象的类型由 C++ 编译器自动推断。在此示例中,类型由 G-API 操作返回值确定,所有这些返回值均为 cv::GMat。
只要有可能,G-API 标准内核都会遵循 OpenCV API 约定,因此 cv::gapi::sobel 采用与 cv::Sobel 相同的参数,cv::gapi::mul 遵循 cv::multiply,依此类推(返回值除外)。
calcGST() 函数的其余部分可以以同样的方式简单实现。以下是其完整源代码
{
auto tmp1 = J11 + J22;
auto tmp2 = J11 - J22;
auto lambda1 = tmp1 + tmp4;
auto lambda2 = tmp1 - tmp4;
imgCoherencyOut = (lambda1 - lambda2) / (lambda1 + lambda2);
}
GMat boxFilter(const GMat &src, int dtype, const Size &ksize, const Point &anchor=Point(-1,-1), bool normalize=true, int borderType=BORDER_DEFAULT, const Scalar &borderValue=Scalar(0))
使用盒状滤波器模糊图像。
GMat phase(const GMat &x, const GMat &y, bool angleInDegrees=false)
计算 2D 向量的旋转角。
GMat sqrt(const GMat &src)
计算数组元素的平方根。
运行 G-API 图
在 G-API 语言中定义了 calcGST() 之后,我们可以基于它构建一个图,然后最终运行它 - 传入图像并获得结果。在执行此操作之前,让我们来看看原始代码是什么样的
Mat imgCoherency, imgOrientation;
calcGST(imgIn, imgCoherency, imgOrientation, W);
imgCoherencyBin = imgCoherency > C_Thr;
inRange(imgOrientation,
Scalar(LowThr),
Scalar(HighThr), imgOrientationBin);
imgBin = imgCoherencyBin & imgOrientationBin;
normalize(imgCoherency, imgCoherency, 0, 255, NORM_MINMAX,
CV_8U);
normalize(imgOrientation, imgOrientation, 0, 255, NORM_MINMAX,
CV_8U);
imshow("原始", imgIn);
imshow("结果", 0.5 * (imgIn + imgBin));
imshow("一致性", imgCoherency);
imshow("方向", imgOrientation);
imwrite("result.jpg", 0.5*(imgIn + imgBin));
imwrite("Coherency.jpg", imgCoherency);
imwrite("Orientation.jpg", imgOrientation);
waitKey(0);
像 calcGST() 这样的基于 G-API 的函数不能直接应用于输入数据,因为它是构造代码,而不是处理代码。要运行计算,需要创建一个 cv::GComputation 类的特殊对象。此对象将我们的 G-API 代码(它是 G-API 数据和操作的组合)包装到一个可调用对象中,类似于 C++11 std::function<>。
cv::GComputation 类具有可以用来定义图形的多个构造函数。通常,用户需要传递图形边界 - 定义 GComputation 的input 和output 对象。然后 G-API 分析从output 到input 的调用流程,并用指定边界之间的操作重建图形。这听起来很复杂,但实际上代码如下所示
calcGST(in, imgCoherency, imgOrientation, W);
cv::GMat imgCoherencyBin = imgCoherency > C_Thr;
cv::GMat imgBin = imgCoherencyBin & imgOrientationBin;
cv::Mat imgOut, imgOutCoherency, imgOutOrientation;
segm.apply(
cv::gin(imgIn),
cv::gout(imgOut, imgOutCoherency, imgOutOrientation));
GComputation 类表示一个被捕获的计算图。GComputation 对象形成 ... 的边界
定义 gcomputation.hpp:121
@ NORM_MINMAX
标志
定义 base.hpp:207
GMat addWeighted(const GMat &src1, double alpha, const GMat &src2, double beta, double gamma, int ddepth=-1)
计算两个矩阵的加权和。
GMat inRange(const GMat &src, const GScalar &threshLow, const GScalar &threshUp)
对每个矩阵元素应用范围级别阈值。
CV_EXPORTS_W bool imwrite(const String &filename, InputArray img, const std::vector< int > ¶ms=std::vector< int >())
将图像保存在指定的文件中。
GRunArgs gin(const Ts &... args)
定义 garg.hpp:275
GProtoInputArgs GIn(Ts &&... ts)
定义 gproto.hpp:96
GRunArgsP gout(Ts &... args)
定义 garg.hpp:280
GProtoOutputArgs GOut(Ts &&... ts)
定义 gproto.hpp:101
请注意,此代码与原始代码略有不同:形成的结果图像也是管道的一部分(使用 cv::gapi::addWeighted 完成)。
此 G-API 管道的结果与原始结果(给定相同的输入图像)完全匹配

使用 G-API 产生的分割结果
G-API 初始版本:完整清单
以下是 G-API 上初始各向异性图像分割端口的完整列表
#include <iostream>
#include <utility>
{
int W = 52;
double C_Thr = 0.43;
int LowThr = 35;
int HighThr = 57;
{
std::cout << "ERROR : Image cannot be loaded..!!" << std::endl;
返回页 -1;
}
calcGST(in, imgCoherency, imgOrientation, W);
cv::GMat imgCoherencyBin = imgCoherency > C_Thr;
cv::GMat imgBin = imgCoherencyBin & imgOrientationBin;
cv::Mat imgOut, imgOutCoherency, imgOutOrientation;
segm.apply(
cv::gin(imgIn),
cv::gout(imgOut, imgOutCoherency, imgOutOrientation));
返回页 0;
}
{
auto tmp1 = J11 + J22;
auto tmp2 = J11 - J22;
auto lambda1 = tmp1 + tmp4;
auto lambda2 = tmp1 - tmp4;
imgCoherencyOut = (lambda1 - lambda2) / (lambda1 + lambda2);
}
@ IMREAD_GRAYSCALE
如果设置,始终将图像转换为单通道灰度图像(编解码器内部转换)。
定义 imgcodecs.hpp:70
CV_EXPORTS_W Mat imread(const String &filename, int flags=IMREAD_COLOR)
从文件中加载图像。
检查初始版本
在将 G-API 初始工作版本算法投入使用后,我们可以使用它来检查和了解 G-API 的工作方式。本章涵盖两个方面:了解图形结构和内存分析。
了解图形结构
G-API 代表“图形 API”,但在以上示例中您有没有提到任何图形?这是最初设计目标之一 - G-API 设计时考虑到了表达式,以使采用和移植过程更直接。编写普通代码时人们通常不会从节点和边考虑问题,因此 G-API 虽然是一个图形 API,但不会强迫其用户这样做。
但是,当cv::GComputation对象被定义时,仍会隐式构建图形。检查生成的图形的外观可能很有用,以检查它是否正确生成并且它是否真正表示了我们的算法。学习图形的结构也很有用,以了解它是否具有任何冗余。
G-API 允许将生成的图形转储到 .dot 文件中,然后再通过流行的开放图形可视化软件 Graphviz 对其进行可视化。
为了将我们的图形转储到 .dot 文件中,在运行应用程序之前将 GRAPH_DUMP_PATH 设置为文件名,例如此类
$ GRAPH_DUMP_PATH=segm.dot ./bin/example_tutorial_porting_anisotropic_image_segmentation_gapi
现在可以使用类似以下命令的 dot 命令可视化此文件
$ dot segm.dot -Tpng -o segm.png
或使用 xdot 交互式地进行查看(请参阅您的发行版/操作系统文档,了解如何安装这些软件包)。
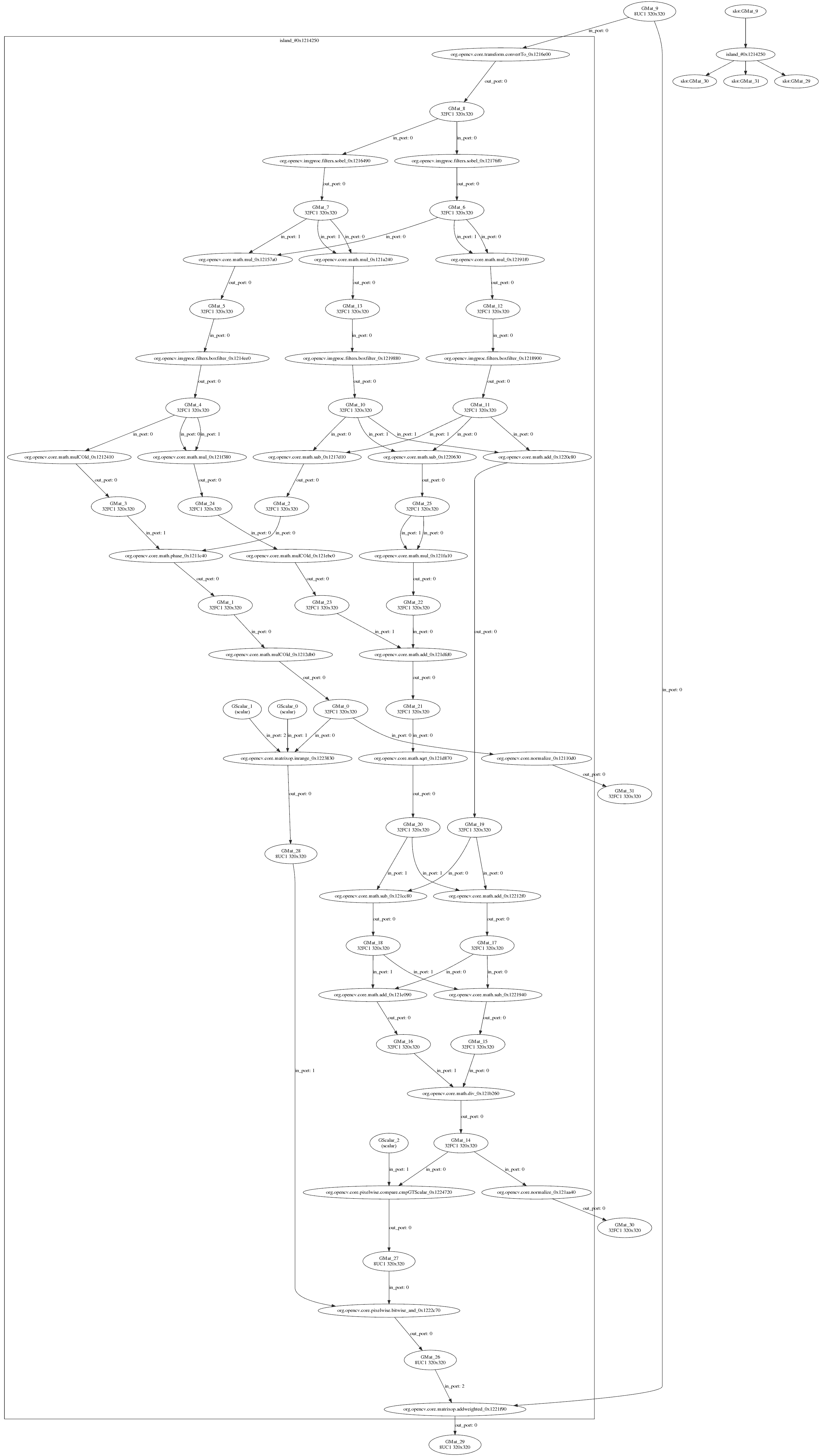
各向异性图像分割图
上图展示了 G-API 内部算法表示的几个有趣方面
- G-API 底层图形是一个二分图:它由运算和数据节点组成,使得数据节点只能连接到运算节点,运算节点只能连接到数据节点,并且单一类型的节点永远不会直接连接。
- 图形是定向的 - 图形中的每条边都有一个方向。
- 图形以数据类型的节点“开始”和“结束”。
- 数据节点只能有一个写者和多个读者。
- 运算节点可以有多个输入,但每个输入都必须具有唯一的端口号(在输入中)。
- 运算节点可以有多个输出,并且每个输出都必须具有唯一的端口号(在输出中)。
测量内存占用
让我们测量并比较算法在其两个版本中的内存占用:基于 G-API 和基于 OpenCV 的版本。目前,G-API 版本也是基于 OpenCV 的版本,因为它回退到内部的 OpenCV 函数。
在 GNU/Linux 上,可以使用 Valgrind 分析应用程序的内存占用。在 Debian/Ubuntu 系统上,可以像这样进行安装(假设您具有管理员权限)
$ sudo apt-get install valgrind massif-visualizer
安装完成后,我们可以轻松地收集这两个算法版本的内存使用情况分析
$ valgrind --tool=massif --massif-out-file=ocv.out ./bin/example_tutorial_anisotropic_image_segmentation
==6101== Massif, a heap profiler
==6101== Copyright (C) 2003-2015, and GNU GPL'd, by Nicholas Nethercote
==6101== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info
==6101== Command: ./bin/example_tutorial_anisotropic_image_segmentation
==6101==
==6101==
$ valgrind --tool=massif --massif-out-file=gapi.out ./bin/example_tutorial_porting_anisotropic_image_segmentation_gapi
==6117== Massif, a heap profiler
==6117== Copyright (C) 2003-2015, and GNU GPL'd, by Nicholas Nethercote
==6117== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info
==6117== Command: ./bin/example_tutorial_porting_anisotropic_image_segmentation_gapi
==6117==
==6117==
完成之后,我们可以使用Massif Visualizer(已在上一步中安装)来检查收集的程序剖面。
以下是算法的原始 OpenCV 版本的可视化内存剖面
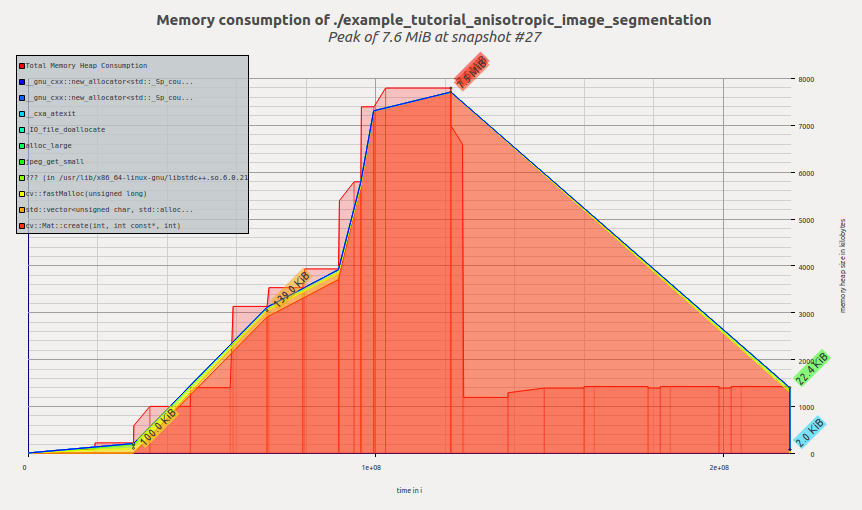
内存剖面:原始各向异性图像分割样本
我们可以看到,在应用程序执行时分配了内存,在 calcGST() 函数中达到峰值;然后,当 calcGST() 完成执行并且所有临时缓冲区都已释放时,占用空间下降。Massif 向我们报告峰值内存消耗为 7.6 MiB。
现在让我们看看 G-API 版本的剖面
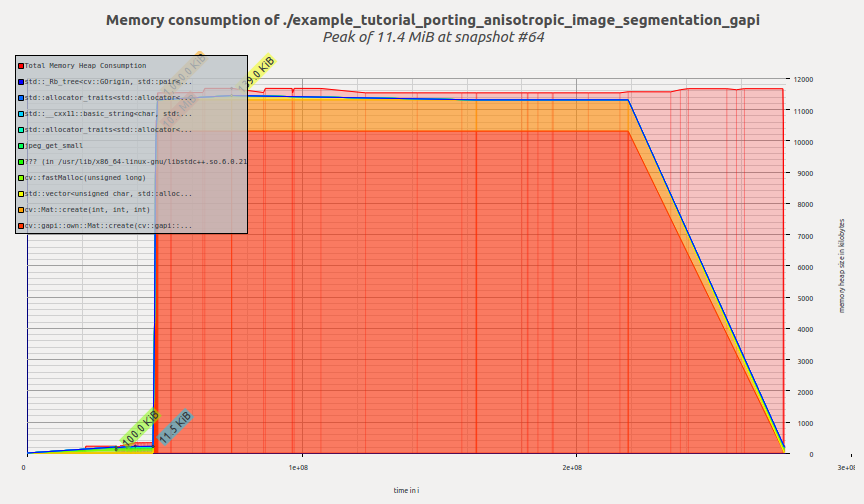
内存剖面:各向异性图像分割样本的 G-API 端口
一旦创建 G-API 运算并开始执行,G-API 就会立即分配所有必需的内存,然后内存剖面保持平坦,直到程序终止。Massif 向我们报告峰值内存消耗为 11.4 MiB。
读者可能会在此时提出一个正确的问题——G-API 这么糟糕吗?为什么要使用它呢?
希望不是。我们在这里看到内存消耗增加的原因是使用基于 OpenCV 的默认朴素后端来执行此图。此后端主要用于快速原型制作和调试算法,然后再进行卸载/进一步优化。
此后端尚未利用任何复杂的内存管理策略,因为它目前还没有达到这一点。在下一章中,我们将了解 Fluid 后端,并了解相同的 G-API 代码如何在完全不同的模型中运行(占用空间缩小到数千字节)。
后端和内核
本章介绍了如何以特殊方式执行 G-API 运算,例如卸载到其他设备或使用特殊智能进行调度。G-API 旨在使其图形可移植,这意味着一旦使用 G-API 术语定义了图形,如果我们要在 CPU 或 GPU 或两个设备上同时运行它,就不需要对其进行任何更改。 G-API high-level overview 和 G-API Kernel API详细阐述了实现这一目标的技术细节。在本章中,我们将利用 G-API Fluid 后端使我们的图形在 CPU 上具有高效缓存。
G-API 将后端定义为知道如何运行内核的较低级实体。后端可能(实际上确实)具有用于编程和集成这些后端的内核的不同内核 API。在此上下文中,内核是运算的实现,该运算在顶级 API 级别上定义(请参见G_TYPED_KERNEL()宏)。
后端是一种了解设备和平台具体信息的设备,并且后端会根据具体信息来执行其内核。例如,可以有 Halide 后端,该后端允许使用 Halide 语言编写(实现)G-API 操作,然后生成适用于 G-API 映射部分的实用的 Halide 代码。
使用流体后端运行图形
OpenCV 4.0 捆绑了两个 G-API 后端 – 我们刚刚使用的默认“OpenCV”和一个特殊的“Fluid”后端。
Fluid 后端对执行进行重新组织,以节省内存并实现接近完美的缓存局部性,实现了所谓执行的“流”模型。
为了开始使用流内核,我们需要首先包含相应的文件头(这些文件头默认不包括在内)
包含了这些文件头后,我们可以形成一个新的内核包并将其指定到 G-API
一个容器类,适用于异构内核实现集合和图形转换。
定义 gkernel.hpp:471
cv::GKernelPackage kernels()
cv::GKernelPackage combine(const cv::GKernelPackage &lhs, const cv::GKernelPackage &rhs)
在 G-API 中,内核(或操作实现)是对象。内核被整理到集合中,或内核包中,由 cv::GKernelPackage 类表示。内核包的主要目的是获取我们在图形中想要使用的内核,并将其作为图形编译选项传递
cv::gout(imgOut, imgOutCoherency, imgOutOrientation),
GCompileArgs compile_args(Ts &&... args)
将参数包中的参数列表包装到编译参数 (cv::GCompileArg) 的向量中...
定义 gcommon.hpp:214
传统的 OpenCV 在逻辑上划分为模块,每个模块都提供一组函数。在 G-API 中,也有“模块”,它们的体现是特定后端提供的内核包。在此示例中,我们向 G-API 传递 Fluid 内核包,以在我们图中利用适当的 Fluid 函数。
可以合并内核包 – 在上例中,我们使用“Core”和“ImgProc”Fluid 内核包,并将它们合并到一个内核包中。请参阅 cv::gapi::combine 上的文档参考。
如果选项中没有指定内核包,G-API 将使用默认包,该包包含默认 OpenCV 实现,因此默认情况下 G-API 图是通过 OpenCV 函数执行的。OpenCV 后端提供的功能覆盖范围比其他任何后端都要广。如果指定了内核包,如本例所示,那么它将与默认内核包合并。这意味着在发生冲突的情况下,用户指定的实现将替换默认实现。
故障排除和自定义
在上述修改之后,(在 OpenCV 4.0 中)应用程序应崩溃并出现类似以下内容的消息
$ ./bin/example_tutorial_porting_anisotropic_image_segmentation_gapi_fluid
调用 terminate 是因为抛出了 'std::logic_error' 实例
what(): .../modules/gapi/src/backends/fluid/gfluidimgproc.cpp:436: 函数 run 中的断言 kernelSize.width == 3 && kernelSize.height == 3 失败
已中止(已转存核心)
Fluid 后端在 OpenCV 4.0 中存在许多限制(请参阅此 Wiki 页面 以了解更最新的状态)。具体来说,此示例中使用的框滤镜仅支持静态 3x3 内核大小。
我们通过避免 G-API 在此示例中使用框滤镜内核的 Fluid 版本,可以轻松解决此问题。它可以通过从我们刚刚创建的内核包中删除适当的内核来完成
fluid_kernels.
remove<cv::gapi::imgproc::GBoxFilter>();
void remove(const cv::gapi::GBackend &backend)
从包中删除与给定后端关联的所有内核。
现在,此内核包没有任何框滤镜内核接口的实现(指定为模板参数)。如上所述,G-API 现在将回退到 OpenCV 来运行此内核。包含此更改后的最终代码现在看上去像
fluid_kernels.
remove<cv::gapi::imgproc::GBoxFilter>();
cv::gout(imgOut, imgOutCoherency, imgOutOrientation),
切换到 Fluid 后端后,让我们检查此示例的内存概要文件。现在看上去就是这样
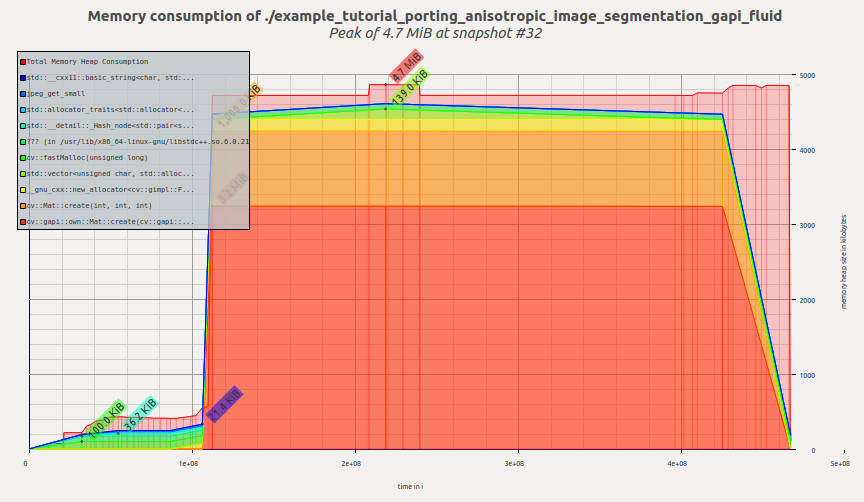
内存概要文件:各向异性图像分割示例的 G-API/Fluid 端口
现在此工具会报告 4.7 MiB,而我们只改了几行代码,而未修改图形本身!与前一次 G-API 结果相比,提升了约 2.4 倍,与原始 OpenCV 版本相比,提升了约 1.6 倍。
我们还来研究下图形的内部表示现在是什么样子的。将图形转储为 .dot 将生成如下可视化
具有 OpenCV 和 Fluid 内核的各向异性图像分割图形
此图形在结构上与它的前一个版本没有差别(从操作和数据对象的角度来看),但可以轻易地注意到改变后的布局(转储的左侧)。
可视化反映了 G-API 如何处理混合图形,也称为异构图形。此图形中的大部分操作都是通过 Fluid 后端实现的,但框过滤器是由 OpenCV 后端执行的。人们可以轻易地看到此图形是否进行了分区(使用矩形)。G-API 根据亲和力对连接的操作进行分组,形成子图(或 G-API 术语中的岛屿),并且我们的顶级图变为多个较小子图的构成。每个后端确定如何执行它的子图(岛屿),因此 Fluid 后端尽可能地优化内存,并且由 OpenCV 框过滤器访问的六个中间缓冲区被完整地分配,而不能进行优化。
总结
本教程演示了 G-API 是什么及其主要设计概念是什么,如何向 G-API 移植算法,以及此后如何利用图形模型优势。
在 OpenCV 4.0 中,G-API 仍处于起始阶段,它更像是所有未来工作的基础,但现在即可使用。
此外,本教程还将通过有关自定义内核编程、并行处理等方面的新章节得到扩展。
 1.9.8 为 OpenCV 生成
1.9.8 为 OpenCV 生成