|
OpenCV 4.10.0
开源计算机视觉
|
正在加载...
正在搜索...
无匹配项
|
OpenCV 4.10.0
开源计算机视觉
|
上一教程: 使用 OpenCV 进行相机校准
下一教程: 交互式相机校准应用程序
| 原作者 | Edgar Riba |
| 兼容性 | OpenCV >= 3.0 |
如今,增强现实是计算机视觉和机器人领域的热门研究主题之一。增强现实中最基本的问题是估计相机相对于物体的姿态,在计算机视觉领域,可以进行 3D 渲染,在机器人领域,可以获取物体的姿态以进行抓取和操作。然而,这并非一个简单的任务,因为图像处理中最常见的问题是,为了解决基本问题,需要应用大量算法或数学运算,而对于人类来说这些问题是简单且直观的。
本教程介绍如何构建一个实时应用程序,以估计相机姿态,从而使用 2D 图像及其 3D 纹理模型跟踪具有六个自由度的纹理物体。
应用程序将包含以下部分:
在计算机视觉中,根据 *n* 个 3D 到 2D 点对应关系估计相机姿态是一个基本且理解良好的问题。该问题最通用的版本需要估计姿态的六个自由度和五个校准参数:焦距、主点、纵横比和倾斜度。可以使用众所周知的直接线性变换 (DLT) 算法,根据至少 6 个对应关系进行确定。然而,该问题存在一些简化,转化为一系列不同的算法,这些算法可以提高 DLT 的精度。
最常见的简化是假设已知校准参数,即所谓的透视-*n*-点问题
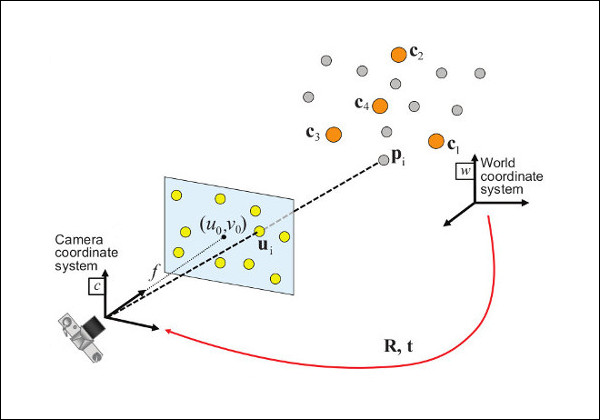
问题描述:给定一组对应关系,包括以世界参考系表示的 3D 点 \(p_i\),以及它们在图像上的 2D 投影 \(u_i\),我们试图检索相机相对于世界的姿态(\(R\) 和 \(t\)) 以及焦距 \(f\)。
OpenCV 提供了四种不同的方法来解决透视-*n*-点问题,这些方法会返回 \(R\) 和 \(t\)。然后,使用以下公式可以将 3D 点投影到图像平面
\[s\ \left [ \begin{matrix} u \\ v \\ 1 \end{matrix} \right ] = \left [ \begin{matrix} f_x & 0 & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1 \end{matrix} \right ] \left [ \begin{matrix} r_{11} & r_{12} & r_{13} & t_1 \\ r_{21} & r_{22} & r_{23} & t_2 \\ r_{31} & r_{32} & r_{33} & t_3 \end{matrix} \right ] \left [ \begin{matrix} X \\ Y \\ Z\\ 1 \end{matrix} \right ]\]
有关如何处理这些方程式的完整文档位于 相机校准和 3D 重建 中。
您可以在 OpenCV 源库的 samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/ 文件夹中找到本教程的源代码。
本教程包含两个主要程序:
模型注册
此应用程序专为那些没有要检测物体的 3D 纹理模型的用户使用。您可以使用此程序创建自己的纹理 3D 模型。此程序仅适用于平面物体,因此如果您要对形状复杂的物体进行建模,则应使用更复杂的软件来创建模型。
应用程序需要要注册物体的输入图像及其 3D 网格。我们还需要提供用于拍摄输入图像的相机的内在参数。所有文件都需要使用绝对路径或应用程序工作目录的相对路径来指定。如果没有指定任何文件,程序将尝试打开提供的默认参数。
应用程序启动后将从输入图像中提取 ORB 特征和描述符,然后使用网格和 Möller–Trumbore 交点算法 计算所找到特征的 3D 坐标。最后,3D 点和描述符存储在 YAML 格式的文件中不同的列表中,每行代表一个不同的点。有关如何存储文件的技术背景,请参阅 使用 XML 和 YAML 文件进行文件输入和输出 教程。

模型检测
此应用程序的目标是根据给定的 3D 纹理模型实时估计物体的姿态。
应用程序启动后将以 YAML 文件格式加载 3D 纹理模型,其结构与模型注册程序中解释的结构相同。从场景中检测和提取 ORB 特征和描述符。然后,使用 cv::FlannBasedMatcher 和 cv::flann::GenericIndex 对场景描述符和模型描述符进行匹配。使用所找到的匹配项以及 cv::solvePnPRansac 函数计算相机的 R 和 t。最后,应用卡尔曼滤波器以剔除不良姿态。
如果您使用样本编译了 OpenCV,则可以在 opencv/build/bin/cpp-tutorial-pnp_detection` 中找到它。然后,您可以运行应用程序并更改一些参数:
例如,您可以运行应用程序并更改 pnp 方法:
以下是实时应用程序代码的详细解释:
读取 3D 纹理物体模型和物体网格。
为了加载纹理模型,我实现了 类 Model,它具有函数 load(),该函数会打开一个 YAML 文件并获取存储的 3D 点及其相应的描述符。您可以在 samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/Data/cookies_ORB.yml 中找到 3D 纹理模型的示例。
在主程序中,模型的加载方式如下:
为了读取模型网格,我实现了 类 Mesh,它具有函数 load(),该函数会打开一个 \(*\).ply 文件并存储物体的 3D 点以及组成的三角形。您可以在 samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/Data/box.ply 中找到模型网格的示例。
在主程序中,网格的加载方式如下:
您也可以加载不同的模型和网格:
从相机或视频获取输入
要进行检测,需要捕获视频。这可以通过加载录制视频来完成,方法是传递视频在您计算机上的绝对路径。为了测试应用程序,您可以在 samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/Data/box.mp4 中找到录制视频。
然后,算法会逐帧计算:
您也可以加载不同的录制视频
从场景中提取ORB特征和描述符
下一步是检测场景特征并提取其描述符。为此,我实现了一个名为 RobustMatcher 的类,它包含用于关键点检测和特征提取的功能。您可以在 samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/src/RobusMatcher.cpp 中找到它。在您的 RobusMatch 对象中,您可以使用 OpenCV 的任何 2D 特征检测器。在本例中,我使用了 cv::ORB 特征,因为它基于 cv::FAST 来检测关键点,并使用 cv::xfeatures2d::BriefDescriptorExtractor 来提取描述符,这意味着它速度快且对旋转具有鲁棒性。您可以在文档中找到有关 ORB 的更多详细信息。
以下代码是实例化和设置特征检测器和描述符提取器的方法
特征和描述符将由 RobustMatcher 在匹配函数内部计算。
使用 Flann 匹配器将场景描述符与模型描述符匹配
这是我们检测算法的第一步。主要思想是将场景描述符与我们的模型描述符匹配,以便了解当前场景中找到的特征的 3D 坐标。
首先,我们必须设置要使用的匹配器。在本例中,使用 cv::FlannBasedMatcher 匹配器,就计算成本而言,它比 cv::BFMatcher 匹配器快,因为我们增加了训练的特征集。然后,对于 FlannBased 匹配器,创建的索引是 Multi-Probe LSH: Efficient Indexing for High-Dimensional Similarity Search,因为 ORB 描述符是二进制的。
您可以调整 LSH 和搜索参数以提高匹配效率
其次,我们必须使用 robustMatch() 或 fastRobustMatch() 函数调用匹配器。使用这两个函数的区别在于它们的计算成本。第一种方法较慢,但在过滤良好匹配方面更稳健,因为它使用了两次比率测试和一次对称性测试。相反,第二种方法更快,但不太稳健,因为它只对匹配项应用了单次比率测试。
以下代码用于获取模型 3D 点及其描述符,然后在主程序中调用匹配器
以下代码对应于 RobustMatcher 类中的 robustMatch() 函数。此函数使用给定的图像来检测关键点并提取描述符,使用 两个最近邻 将提取的描述符与给定的模型描述符匹配,反之亦然。然后,将比率测试应用于这两个方向的匹配项,以移除那些距离比率(第一个最佳匹配和第二个最佳匹配之间的距离比率)大于给定阈值的匹配项。最后,应用对称性测试以移除非对称匹配项。
在匹配项过滤后,我们必须使用获得的 DMatches 向量从找到的场景关键点和我们的 3D 模型中减去 2D 和 3D 对应关系。有关 cv::DMatch 的更多信息,请查看文档。
您也可以更改比率测试阈值、要检测的关键点数以及是否使用稳健匹配器
使用 PnP + Ransac 进行姿态估计
有了 2D 和 3D 对应关系后,我们必须应用 PnP 算法来估计相机姿态。之所以要使用 cv::solvePnPRansac 而不是 cv::solvePnP,是因为匹配后并非所有找到的对应关系都是正确的,而且很可能存在错误的对应关系,也称为 离群值。 随机样本一致性 或 Ransac 是一种非确定性迭代方法,它从观察到的数据中估计数学模型的参数,随着迭代次数的增加,产生近似结果。应用 Ransac 后,将消除所有 离群值,然后以一定概率估计相机姿态,以获得良好的解决方案。
对于相机姿态估计,我实现了一个名为 PnPProblem 的类。此类具有 4 个属性:给定的校准矩阵、旋转矩阵、平移矩阵和旋转-平移矩阵。您用于估计姿态的摄像头的内在校准参数是必要的。要获取参数,您可以查看 使用方形棋盘进行相机校准 和 使用 OpenCV 进行相机校准 教程。
以下代码是在主程序中声明 PnPProblem 类 的方法
以下代码是 PnPProblem 类 初始化其属性的方法
OpenCV 提供四种 PnP 方法:ITERATIVE、EPNP、P3P 和 DLS。根据应用程序类型,估计方法会有所不同。如果我们想要创建一个实时应用程序,EPNP 和 P3P 方法更合适,因为它们在寻找最优解方面比 ITERATIVE 和 DLS 更快。但是,EPNP 和 P3P 在平面表面方面不太鲁棒,有时姿态估计似乎有镜像效果。因此,在本教程中,由于要检测的对象具有平面表面,因此使用了 ITERATIVE 方法。
OpenCV RANSAC 实现需要您提供三个参数:1) 算法停止前的最大迭代次数,2) 允许观察到的点投影和计算出的点投影之间的最大距离(视为内点),3) 获得良好结果的置信度。您可以调整这些参数以改进算法的性能。增加迭代次数将获得更准确的解,但找到解所需的时间更长。增加重投影误差将减少计算时间,但您的解将不准确。降低置信度,您的算法将更快,但获得的解将不准确。
以下参数适用于此应用程序
以下代码对应于estimatePoseRANSAC() 函数,该函数属于PnPProblem 类。此函数根据一组 2D/3D 对应关系、要使用的所需 PnP 方法、输出内点容器和 Ransac 参数来估计旋转和平移矩阵
以下代码是主算法的第 3 步和第 4 步。第一个调用上面的函数,第二个从 RANSAC 中获取输出内点向量以获取用于绘图的 2D 场景点。如代码所示,我们必须确保在有匹配的情况下应用 RANSAC,否则,由于任何 OpenCV 错误,函数 cv::solvePnPRansac 会崩溃。
最后,一旦估计出相机姿态,我们就可以使用 \(R\) 和 \(t\) 来计算给定 3D 点(以世界参考系表示)在图像上的 2D 投影,方法是使用理论中显示的公式。
以下代码对应于backproject3DPoint() 函数,该函数属于PnPProblem 类。该函数将给定以世界参考系表示的 3D 点反向投影到 2D 图像上
上述函数用于计算对象Mesh的所有 3D 点,以显示对象的姿态。
您也可以更改 RANSAC 参数和 PnP 方法
用于错误姿态拒绝的线性卡尔曼滤波器
在计算机视觉或机器人领域,由于某些传感器误差,在应用检测或跟踪技术后,通常会获得不良结果。为了避免本教程中出现的这些不良检测,解释了如何实现线性卡尔曼滤波器。在检测到一定数量的内点后,将应用卡尔曼滤波器。
您可以找到更多关于 卡尔曼滤波器 的信息。在本教程中,使用了基于 用于位置和方向跟踪的线性卡尔曼滤波器 的 cv::KalmanFilter 的 OpenCV 实现来设置动态模型和测量模型。
首先,我们必须定义状态向量,它将有 18 个状态:位置数据 (x,y,z) 及其一阶和二阶导数(速度和加速度),然后以三个欧拉角 (roll, pitch, jaw) 的形式添加旋转,以及它们的一阶和二阶导数(角速度和角加速度)
\[X = (x,y,z,\dot x,\dot y,\dot z,\ddot x,\ddot y,\ddot z,\psi,\theta,\phi,\dot \psi,\dot \theta,\dot \phi,\ddot \psi,\ddot \theta,\ddot \phi)^T\]
其次,我们必须定义测量数量,它将为 6 个:从 \(R\) 和 \(t\) 中,我们可以提取 \((x,y,z)\) 和 \((\psi,\theta,\phi)\)。此外,我们必须定义要应用于系统的控制操作的数量,在本例中为零。最后,我们必须定义测量之间的微分时间,在本例中为 \(1/T\),其中T 是视频的帧率。
以下代码对应于卡尔曼滤波器的初始化。首先,设置过程噪声、测量噪声和误差协方差矩阵。其次,设置状态转移矩阵,它是动态模型,最后设置测量矩阵,它是测量模型。
您可以调整过程噪声和测量噪声来提高卡尔曼滤波器的性能。当测量噪声减小时,算法收敛速度会更快,使其对不良测量值敏感。
以下代码是主算法的第 5 步。当经过Ransac后得到的内点数量超过阈值时,测量矩阵将被填充,然后卡尔曼滤波器将被更新。
以下代码对应于fillMeasurements()函数,它将测量的旋转矩阵转换为欧拉角,并填充测量矩阵以及测量的平移向量
以下代码对应于updateKalmanFilter()函数,该函数更新卡尔曼滤波器并设置估计的旋转矩阵和平移向量。估计的旋转矩阵来自估计的欧拉角到旋转矩阵。
第六步是设置估计的旋转平移矩阵
最后一步是可选的,就是绘制找到的姿态。为此,我实现了一个函数来绘制所有网格 3D 点以及额外的参考轴。
您还可以修改最小内点来更新卡尔曼滤波器
以下视频是使用以下参数使用解释的检测算法进行实时姿态估计的结果。
您可以在 YouTube 上观看实时姿态估计。
 1.9.8
1.9.8