|
OpenCV 4.11.0
开源计算机视觉库
|
加载中…
搜索中…
无匹配项
|
OpenCV 4.11.0
开源计算机视觉库
|
上一篇教程: 条码识别
下一篇教程: 用于非线性可分数据的支持向量机
| 原作者 | Fernando Iglesias García |
| 兼容性 | OpenCV >= 3.0 |
在本教程中,您将学习如何
支持向量机(SVM)是一种判别分类器,由分离超平面正式定义。换句话说,给定标记的训练数据(监督学习),该算法输出一个最优超平面,该超平面对新的示例进行分类。
获得的超平面在什么意义上是最优的?让我们考虑以下简单问题
对于属于两个类别之一的线性可分2D点集,找到一条分离直线。
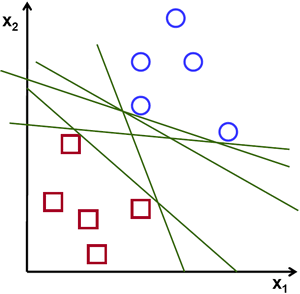
在上图中,您可以看到存在多条直线可以解决这个问题。其中任何一条都比其他更好吗?我们可以直观地定义一个标准来估计这些直线的价值:如果一条直线经过过于靠近点的位置,那么它将对噪声敏感,并且不会正确泛化。 因此,我们的目标应该是找到一条尽可能远离所有点的直线。
然后,SVM算法的操作基于寻找能够给出与训练示例最大最小距离的超平面。这个距离的两倍在SVM理论中被称为裕度。因此,最优分离超平面最大化训练数据的裕度。
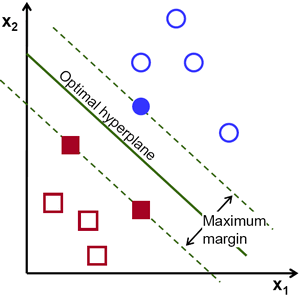
让我们介绍用于正式定义超平面的符号
\[f(x) = \beta_{0} + \beta^{T} x,\]
其中\(\beta\)被称为权重向量,\(\beta_{0}\)被称为偏差。
通过对\(\beta\)和\(\beta_{0}\)进行缩放,可以以无限多种不同的方式表示最优超平面。按照约定,在超平面所有可能的表示中,选择的是
\[|\beta_{0} + \beta^{T} x| = 1\]
其中\(x\)表示最靠近超平面的训练示例。通常,最靠近超平面的训练示例称为支持向量。这种表示称为规范超平面。
现在,我们使用几何结果,该结果给出点\(x\)和超平面\((\beta, \beta_{0})\)之间的距离
\[\mathrm{distance} = \frac{|\beta_{0} + \beta^{T} x|}{||\beta||}.\]
特别是对于规范超平面,分子等于1,并且到支持向量的距离是
\[\mathrm{distance}_{\text{ support vectors}} = \frac{|\beta_{0} + \beta^{T} x|}{||\beta||} = \frac{1}{||\beta||}.\]
回想一下,上一节中介绍的裕度,这里表示为\(M\),是到最接近示例距离的两倍
\[M = \frac{2}{||\beta||}\]
最后,最大化\(M\)的问题等同于在某些约束条件下最小化函数\(L(\beta)\)的问题。约束条件模拟了超平面正确分类所有训练示例\(x_{i}\)的要求。形式上,
\[\min_{\beta, \beta_{0}} L(\beta) = \frac{1}{2}||\beta||^{2} \text{ 受制于 } y_{i}(\beta^{T} x_{i} + \beta_{0}) \geq 1 \text{ } \forall i,\]
其中\(y_{i}\)表示每个训练示例的标签。
这是一个拉格朗日优化问题,可以使用拉格朗日乘子来求解最优超平面的权重向量\(\beta\)和偏差\(\beta_{0}\)。
本练习的训练数据由一组属于两个不同类别之一的带标签的二维点组成;其中一个类别由一个点组成,另一个类别由三个点组成。
稍后将使用的函数cv::ml::SVM::train要求训练数据存储为浮点数的cv::Mat对象。因此,我们根据上面定义的数组创建这些对象。
设置SVM的参数
在本教程中,我们介绍了在最简单的情况下SVM的理论,即训练样本分散到两个线性可分的不同类别中。但是,SVM可以用于各种各样的问题(例如,具有非线性可分数据的的问题,使用核函数来提高样本维数的SVM等)。因此,在训练SVM之前,我们必须定义一些参数。这些参数存储在cv::ml::SVM类的对象中。
这里
SVM分类的区域
方法 cv::ml::SVM::predict 用于使用训练好的 SVM 对输入样本进行分类。在本例中,我们使用此方法根据 SVM 的预测结果对空间进行着色。换句话说,程序遍历图像,将其像素解释为笛卡尔平面上的点。每个点根据 SVM 预测的类别着色;如果是标签为 1 的类别则为绿色,如果是标签为 -1 的类别则为蓝色。
支持向量
这里我们使用几种方法来获取有关支持向量的信息。方法 cv::ml::SVM::getSupportVectors 获取所有支持向量。我们在这里使用此方法来查找作为支持向量的训练样本并突出显示它们。
