|
OpenCV 4.11.0
开源计算机视觉库
|
加载中…
搜索中…
无匹配项
|
OpenCV 4.11.0
开源计算机视觉库
|
上一篇教程: 使用G-API的交互式人脸检测流水线
下一篇教程: 使用G-API实现人脸美化算法
在本教程中,您将学习
本教程基于 基于梯度结构张量的各向异性图像分割.
在我们开始之前,让我们回顾一下原始算法的实现
函数calcGST()显然是一个图像处理流水线
考虑到以上几点,calcGST() 是一个很好的起始点。在原始代码中,其原型定义如下
使用G-API,我们可以将其定义为:
重要的是要理解,基于G-API的calcGST()的新版本只会生成一个计算图,这与它原来的版本不同,原来的版本实际上是计算值的。这是一个主要的区别——像这样的基于G-API的函数用于构建图,而不是处理实际数据。
让我们从计算J矩阵开始实现calcGST()。原始代码如下所示
在这里,我们需要为每个新的操作声明输出对象(参见cv::Mat::convertTo的结果img,以及cv::Sobel和cv::multiply的结果imgDiffX和其他结果)。
G-API的等效代码如下:
这段代码演示了G-API和传统OpenCV之间的以下语法差异:
注意——这段代码也使用了`auto`——中间对象的类型,如`img`、`imgDiffX`等,由C++编译器自动推断。在这个例子中,类型由G-API操作的返回值决定,它们都是cv::GMat。
G-API标准内核尽可能遵循OpenCV API约定——因此cv::gapi::sobel采用与cv::Sobel相同的参数,cv::gapi::mul遵循cv::multiply,等等(除了返回值)。
calcGST()函数的其余部分可以以相同的方式轻松实现。以下是其完整的源代码:
在 G-API 语言中定义 calcGST() 后,我们可以基于它构建一个图,最终运行它——传入输入图像并获得结果。在运行之前,让我们看看原始代码是什么样的。
像 calcGST() 这样的基于 G-API 的函数不能直接应用于输入数据,因为它是一个构造代码,而不是处理代码。为了运行计算,需要创建一个 cv::GComputation 类的特殊对象。这个对象将我们的 G-API 代码(它是 G-API 数据和操作的组合)包装成一个可调用对象,类似于 C++11 std::function<>。
cv::GComputation 类有很多构造函数可用于定义一个图。通常,用户需要传递图的边界——输入和输出对象,GComputation 就是基于它们定义的。然后 G-API 分析从输出到输入的调用流程,并重建带有指定边界之间操作的图。这听起来可能很复杂,但实际上代码是这样的:
请注意,这段代码与原始代码略有不同:形成结果图像也是管道的一部分(使用 cv::gapi::addWeighted 完成)。
这个 G-API 管道的结果与原始结果完全一致(给定相同的输入图像)。

以下是G-API上各向异性图像分割初始版本的完整列表
在我们的算法使用G-API运行的初始版本之后,我们可以用它来检查和学习G-API是如何工作的。本章涵盖两个方面:理解图结构和内存分析。
G-API代表“图形API”,但是你在上面的例子中提到任何图形了吗?这是最初的设计目标之一——G-API的设计理念是表达式,以使采用和移植过程更直接。人们在编写普通代码时通常不会考虑节点和边,因此G-API虽然是图形API,但不会强迫用户这样做。
然而,当定义cv::GComputation对象时,仍然会隐式地构建一个图。检查生成的图是否正确生成以及它是否真正表示我们的算法可能很有用。学习图的结构以查看它是否具有任何冗余也很有用。
G-API允许将生成的图形转储到.dot文件,然后可以使用流行的开放图形可视化软件Graphviz进行可视化。
为了将我们的图转储到.dot文件,在运行应用程序之前将GRAPH_DUMP_PATH设置为文件名,例如:
$ GRAPH_DUMP_PATH=segm.dot ./bin/example_tutorial_porting_anisotropic_image_segmentation_gapi
现在可以使用以下dot命令可视化此文件:
$ dot segm.dot -Tpng -o segm.png
或使用xdot交互式查看(请参阅您的发行版/操作系统文档,了解如何安装这些软件包)。
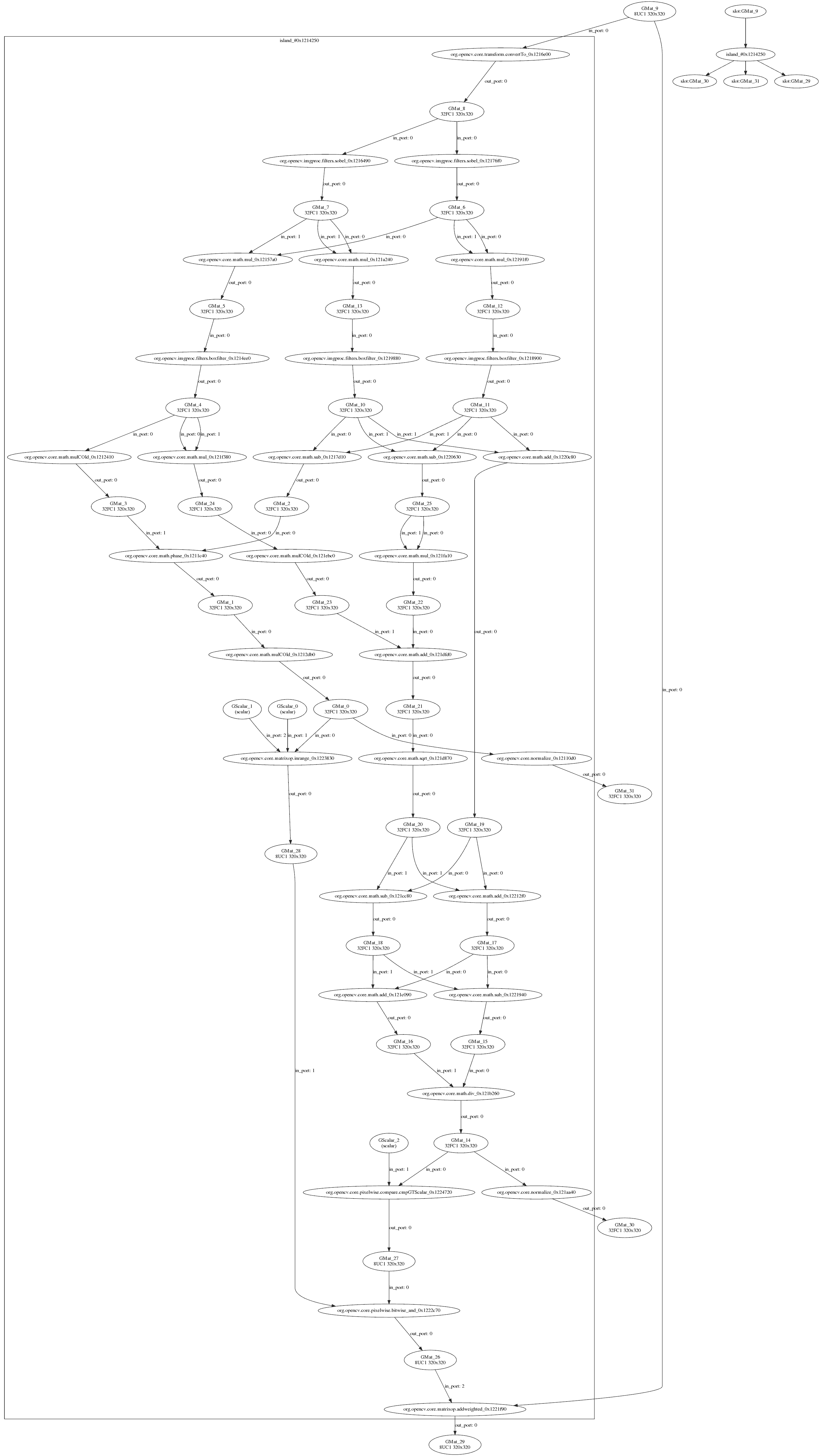
上图演示了G-API内部算法表示的许多有趣方面
让我们测量和比较算法在两个版本中的内存占用:基于G-API的版本和基于OpenCV的版本。目前,G-API版本也是基于OpenCV的,因为它在内部回退到OpenCV函数。
在GNU/Linux上,可以使用Valgrind分析应用程序的内存占用。在Debian/Ubuntu系统上,可以这样安装(假设您具有管理员权限):
$ sudo apt-get install valgrind massif-visualizer
安装完成后,我们可以轻松地为我们的两个算法版本收集内存配置文件:
$ valgrind --tool=massif --massif-out-file=ocv.out ./bin/example_tutorial_anisotropic_image_segmentation ==6101== Massif, a heap profiler ==6101== Copyright (C) 2003-2015, and GNU GPL'd, by Nicholas Nethercote ==6101== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info ==6101== Command: ./bin/example_tutorial_anisotropic_image_segmentation ==6101== ==6101== $ valgrind --tool=massif --massif-out-file=gapi.out ./bin/example_tutorial_porting_anisotropic_image_segmentation_gapi ==6117== Massif, a heap profiler ==6117== Copyright (C) 2003-2015, and GNU GPL'd, by Nicholas Nethercote ==6117== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info ==6117== Command: ./bin/example_tutorial_porting_anisotropic_image_segmentation_gapi ==6117== ==6117==
完成后,我们可以使用Massif Visualizer(在上一步中安装)检查收集的配置文件。
以下是算法原始OpenCV版本的可视化内存配置文件:
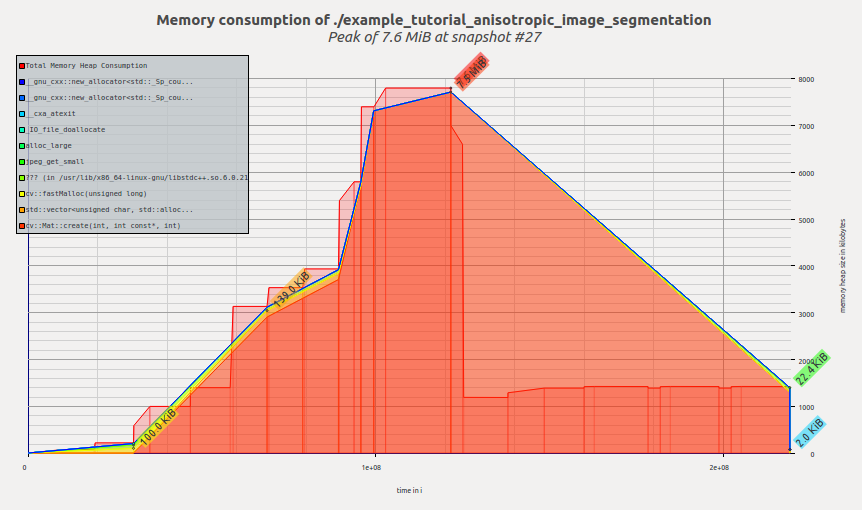
我们看到内存是在应用程序执行时分配的,在calcGST()函数中达到峰值;然后,随着calcGST()完成执行并释放所有临时缓冲区,占用空间下降。Massif报告我们的峰值内存消耗为7.6 MiB。
现在让我们看看G-API版本的配置文件:
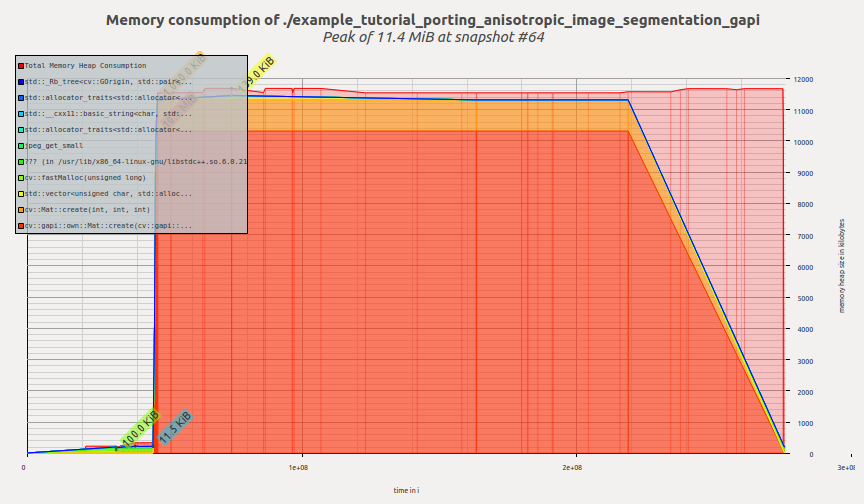
一旦创建G-API计算并开始执行,G-API就会一次性分配所有需要的内存,然后内存配置文件保持平坦,直到程序终止。Massif报告我们的峰值内存消耗为11.4 MiB。
读者此时可能会问一个正确的问题——G-API真的那么糟糕吗?为什么还要使用它呢?
希望不是这样。我们在这里看到内存消耗增加的原因是使用了默认的基于OpenCV的朴素后端来执行此图。此后端主要用于在卸载/进一步优化之前快速原型设计和调试算法。
此后端目前还没有使用任何复杂的内存管理策略,因为它目前不是它的重点。在下一章中,我们将了解Fluid后端,并了解相同的G-API代码如何在完全不同的模型中运行(并将占用空间缩小到几千字节)。
本章介绍如何以特殊方式执行G-API计算——例如卸载到另一个设备,或使用特殊的智能进行调度。G-API旨在使其图形可移植——这意味着一旦以G-API术语定义了图形,如果我们想在CPU或GPU上或同时在这两个设备上运行它,则不需要对其进行任何更改。G-API高级概述和G-API内核API阐述了使这成为可能的更多技术细节。在本章中,我们将使用G-API Fluid后端使我们的图在CPU上具有缓存效率。
G-API将后端定义为知道如何运行内核的较低级别实体。后端可能有(实际上确实有)不同的内核API,用于为这些后端编程和集成内核。在这种情况下,内核是操作的实现,在顶级API级别定义(参见G_TYPED_KERNEL()宏)。
后端是一个了解设备和平台细节并考虑到这些细节执行其内核的实体。例如,可能存在Halide后端,它允许使用Halide语言编写(实现)G-API操作,然后为G-API图中映射良好的部分生成功能性Halide代码。
OpenCV 4.0捆绑了两个G-API后端——我们刚刚使用的默认“OpenCV”和一个特殊的“Fluid”后端。
Fluid后端重新组织执行以节省内存并实现接近完美的缓存局部性,从而实现所谓的“流”执行模型。
为了开始使用Fluid内核,我们首先需要包含相应的头文件(默认情况下不包含):
包含这些头文件后,我们可以形成一个新的内核包并将其指定给G-API
在G-API中,内核(或操作实现)是对象。内核被组织成集合,或内核包,由类cv::GKernelPackage表示。内核包的主要目的是捕获我们想在图中使用的内核,并将其作为图编译选项传递。
传统的OpenCV在逻辑上被划分为模块,每个模块提供一组函数。在G-API中,也有“模块”,它们表示为特定后端提供的内核包。在这个例子中,我们将Fluid内核包传递给G-API,以在我们的图中使用合适的Fluid函数。
内核包是可组合的——在上面的例子中,我们获取“核心”和“图像处理”Fluid内核包,并将它们组合成一个。参见关于cv::gapi::combine的文档参考。
如果选项中没有指定内核包,G-API将使用默认包,该包包含默认的OpenCV实现,因此G-API图默认情况下通过OpenCV函数执行。OpenCV后端提供的功能覆盖范围比任何其他后端都广。如果指定了内核包,就像在这个例子中一样,那么它将与默认包组合。这意味着在发生冲突的情况下,用户指定的实现将替换默认实现。
在进行上述修改后(在OpenCV 4.0中),应用程序应该会崩溃,并显示类似这样的消息
在OpenCV 4.0中,Fluid后端有一些限制(有关最新的状态,请参见此wiki页面)。特别是,此示例中使用的Box滤波器仅支持静态3x3内核大小。
我们可以通过避免在该示例中使用Fluid版本的Box滤波器内核来轻松克服此问题。这可以通过从我们刚刚创建的内核包中删除相应的内核来实现。
现在这个内核包没有任何Box滤波器内核接口的实现(指定为模板参数)。如上所述,G-API现在将回退到OpenCV来运行此内核。进行此更改后的结果代码如下所示。
让我们检查一下切换到Fluid后端后此示例的内存配置文件。现在看起来像这样。
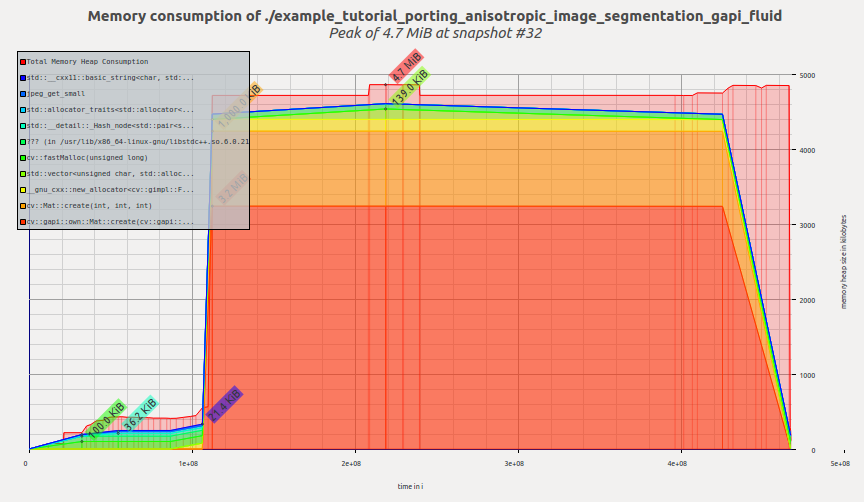
现在该工具报告4.7MiB——我们只更改了代码中的几行,而没有修改图本身!与之前的G-API结果相比,这是一个〜2.4倍的改进,与原始OpenCV版本相比,这是一个〜1.6倍的改进。
让我们也检查一下图的内部表示现在是什么样子。将图转储到.dot将产生这样的可视化结果。
这个图在结构上与其之前的版本(就操作和数据对象而言)没有区别,尽管布局的变化(在转储的左侧)很容易注意到。
可视化反映了G-API如何处理混合图,也称为异构图。此图中的大多数操作都是用Fluid后端实现的,但Box滤波器是由OpenCV后端执行的。可以很容易地看出图是被划分了的(用矩形)。G-API根据操作的亲和性对它们进行分组,形成子图(或G-API术语中的岛屿),而我们的顶级图成为多个较小子图的组合。每个后端都确定其子图(岛屿)如何执行,因此Fluid后端尽可能优化内存,而OpenCV Box滤波器访问的六个中间缓冲区被完全分配,并且无法被优化。
本教程演示了什么是G-API及其关键设计理念,如何将算法移植到G-API,以及如何利用图模型的优势。
在OpenCV 4.0中,G-API仍处于起步阶段——它更多的是未来所有工作的基础,尽管现在已经可以使用了。
此外,本教程将扩展新的章节,内容包括自定义内核编程、并行处理等等。